Unified Grid: How We Re-Architected Slack for Our Largest Customers

All software is built atop a core set of assumptions. As new code is added and new use-cases emerge, software can become unmoored from those assumptions. When this happens, a fundamental tension arises between revisiting those foundational assumptions—which usually entails a lot of work—or trying to support new behavior atop the existing architecture. The latter approach is usually advised, to save time and reduce risk.
However, there are times when it’s worth revising the core architecture of a large software application. Recently at Slack we did just that, taking a step back to change how our backend and clients (the desktop and mobile applications) work on a foundational level.
Slack launched in 2013 with a simple architecture—each user belonged to a single workspace, where they joined channels and sent messages. To view messages from a different workspace (that you were also logged in to), you needed to click into that workspace.
This model held until 2017, when we released Enterprise Grid, which lets Slack’s largest customers divide their organizations into multiple workspaces, each with a particular focus. In the beginning Enterprise Grid users were usually in just a single workspace, but over time usage patterns changed, and today these users often belong to several workspaces. Simultaneously, we’ve built ways for Slack clients to share data across multiple workspaces on the same Grid, such as the Threads and Unreads views and cross-workspace channels.
This led to a natural question: if data is shared between multiple workspaces on the same Grid, and users need to switch between those workspaces to do their jobs, why not instead provide a single, unified view of all the data a user can access within their Grid? Not only would this provide a superior user experience, it would eliminate a class of bugs caused by syncing org-wide data across multiple workspaces. And it would improve performance, since data for multiple workspaces could be loaded in a single API request.
With this insight, the Unified Grid project was born. But because Slack was architected with the assumption that almost all data is particular to a single workspace, it was initially unclear whether Unified Grid was even feasible. Still, we decided that because the product continued to push against the limits of a workspace-centric architecture, we had to try.
Enterprise Grid: The evolution of Slack’s architecture
To understand what made Unified Grid such an ambitious project, it’s worth zooming out to investigate Slack’s architecture and how it’s evolved over the years.
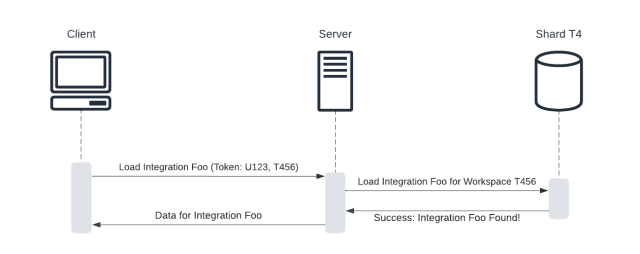
In 2013, Slack launched with a relatively simple model. Users belonged to workspaces within which they joined channels and sent messages. Each workspace represented a customer, and all the data for a particular workspace was stored on a single database server, or “shard.” Slack clients authenticated their API requests using session tokens containing the user ID and workspace ID (called “workspace tokens”); the backend then parsed the workspace ID and used it to associate each API request with a workspace, route queries to that workspace’s database shard and perform access control. This model also extended to the client, where the data for each workspace was stored in a separate repository with distinct login sessions.
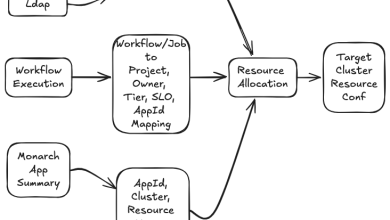
As Slack grew, we noticed that individual divisions within the same company often created separate Slack workspaces. We wanted to give companies a simple way to administer these workspaces via a single UI, where they could enforce security policies and handle billing across their entire organization. Thus, Enterprise Grid, our solution for our largest and most complex customers, was born.
To support Enterprise Grid, we introduced the concept of an “org” that effectively served as a “parent” to multiple workspaces. Users still navigated Slack from the perspective of an individual workspace, but now it was also possible for data to be stored at the org level. For example, customers could create cross-workspace (XWS) channels, which were stored on the org’s database shard and visible across multiple workspaces. This meant that the Slack backend was required to query data on both the workspace shard and, if absent there, on the org shard (for workspaces which are part of an Enterprise Grid). Because Enterprise Grid users could be assigned permissions on the level of the workspace and/or org, the backend also had to check permissions at both the workspace and org-level.
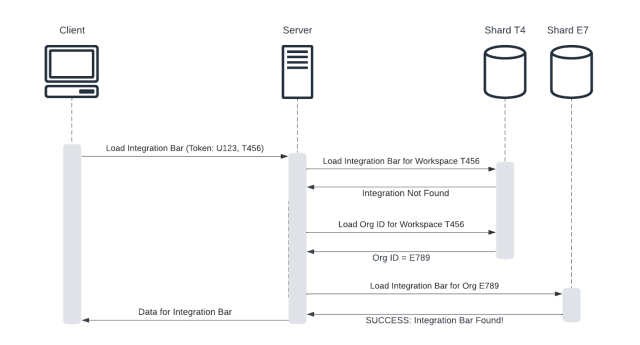
The changing landscape
Initially, since end users were usually in a single workspace, their experience didn’t change much in Enterprise Grid. However, over time the way customers use Slack has evolved. Now, a significant portion of users do belong to multiple workspaces on the grid, which led to context switching and missed activity.
We wanted to address these problems, and several infrastructure-level changes we’d made suggested a way forward. With the Vitess migration, we began sharding data along axes other than workspace or org ID, meaning that the workspace or org was no longer required to route queries to the appropriate database shard for our most important tables. We also enhanced our real-time messaging (RTM) stack to remove the need to fan-out org-wide data to every workspace on the grid (and some of our largest customers have thousands of workspaces!). Finally, we updated clients to share org-wide data across all workspaces within their grid. Leveraging these infrastructure investments, we built views that aggregated content from multiple workspaces, like our Threads and Unreads view.
However, even with these improvements, our workspace-centric architecture still caused significant frustration. We knew that to truly solve the problem, we’d need to move to an org-wide architecture, even though this would entail updating thousands of APIs, database queries, and permissions checks.
Prototyping the path
Execs—not to mention engineers—were understandably concerned about the cost of Unified Grid, and not convinced that the payoff would be worth the effort. Therefore, rather than start by tackling what were potentially thousands of broken APIs, we decided to build a proof of concept to better understand the benefits of Unified Grid and the work that would be required to ship it end-to-end.
At Slack, we call this prototyping the path—that is, building incrementally, proving out and refining our ideas as we go. Because we are some of the heaviest users of Slack, we knew that if we could use Unified Grid in our day-to-day work, we’d start getting good signals about what did and didn’t work. And as the project grew in maturity, we could opt in more of our peers, gathering valuable feedback from them.
First, we needed to be able to boot the Slack client in Unified Grid mode, with an org-wide view of all the user’s channels rather than a workspace-scoped view. To this end, we built a new boot API which returns data for all the workspaces and channels the user belongs to across the entire Grid. We updated clients to store this boot data at the org-level, since users in Unified Grid no longer navigate from the perspective of a single Grid workspace at a time.
Once the client could boot, we updated our homegrown API framework such that an API could be marked compatible with the new Unified Grid client. We then began fixing APIs and client-side checks as we encountered issues, prioritizing those that impacted our day-to-day work. We had a few primary strategies for fixing broken APIs:
- If an API did not rely on workspace context for routing—perhaps because it had been migrated to a new sharding scheme during the Vitess migration—we allowed it to be called in Unified Grid and confirmed that the query still behaved correctly. For example, because the messages table is now sharded by channel ID, we could efficiently fetch messages for a channel without significant changes.
- If an API acted directly on a workspace, we could often prompt users to select a workspace and then pass that workspace to the API. For example, we updated the channel creation flow such that the user must select the workspace in which the channel should be created, since the workspace can no longer be inferred from the state of the client.
- Finally, if all else failed, we could iterate over the user’s relevant workspaces, attempting to resolve the query against each workspace’s shard. Because most users are in only a handful of workspaces, this approach is surprisingly performant. However, there is a long tail of users in hundreds of workspaces. Because such users are generally administrators who do not interact with all those workspaces, we decided to cap the number of “relevant” workspaces at 50 and allow users to manually configure this list. Restricting the relevant workspaces for each user ensures reasonable performance and makes Slack usable for these outliers.
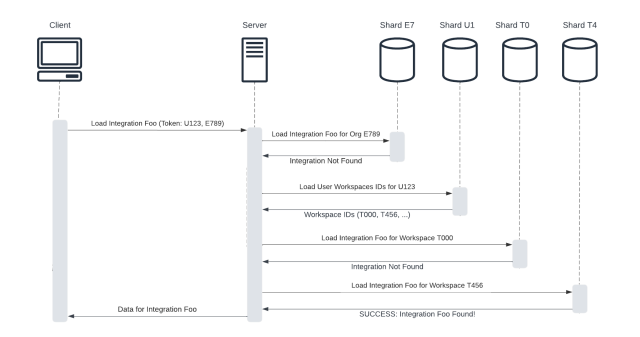
Although our prototype had lots of rough edges, we felt the benefit of reduced context switching and a simpler UX. From there, we started opting in more coworkers, eventually inviting execs like our then-CEO Stewart Butterfield to try the new client. His feedback summed up how we felt: “This is obviously better.”
From prototype to production
As mentioned above, Unified Grid potentially impacted every API and permission check invoked by the Slack client. It would require significant effort from scores of engineers across most of Slack’s product engineering teams to ensure these API and permission checks continued to behave correctly. Simultaneously, we were building IA4, a redesign of the Slack client which introduced our Activity, DMs, and Later tabs. In order to avoid subjecting customers to separate large changes at the same time, Unified Grid became a foundational component of IA4, and with it a top company priority.
We began with spreadsheets listing all APIs which were invoked by Slack clients as well as all permission checks performed by clients and the backend, dividing the work among various related product teams. In keeping with prototyping the path, we asked engineers to take two passes over each API: a first pass to make the API work well enough for internal usage, and then—perhaps weeks later—a second pass to ensure the integration tests, permissions checks and other edge-cases behaved correctly. This two-phase approach allowed us to manually verify and get a feel for functionality which was not entirely ready for primetime.
The core team now pivoted our work away from prototyping to more scalably support the migration effort with tools and frameworks:
Docs: Most importantly, we put together a detailed guide with step-by-step instructions for ensuring that an API behaves correctly in Unified Grid, including the strategies for fixing APIs listed in the “Prototyping the path” section.
Tests: We created a parallel integration test suite which ran all our existing integration tests using org context instead of workspace context. This let us reuse thousands of tests rather than rewriting them from the ground up. As expected, hundreds of test suites were broken initially, providing us with a concrete list of test suites to fix as part of marking an API compatible with Unified Grid.
Helpers: We added a number of convenience helpers to correctly fetch channels and perform permissions checks across all a user’s workspaces on their Enterprise Grid, on both clients and the backend. For example, to check whether a user can act as an admin within a cross-workspace channel, these helpers check whether the user is a workspace admin in any of the workspaces with which the channel is shared or is an admin at the org-level.
Client Infrastructure: In addition to the work needed to support these permissions checks, clients also required new infrastructure to migrate workspace-scoped repositories to the new data model. The clients solved this problem in different ways: some clients added an org-level data store but continued to save some data in workspace-scoped repositories, while other clients moved everything to an org-wide store. These data migrations could be completed and shipped in parallel with the overall Unified Grid project, which allowed us to de-risk the project itself.

Conclusion
By Summer 2023, Unified Grid was in a place where much of the company was using it for their day-to-day work. We began rolling out to customers in Fall 2023 and completed the rollout in March 2024. What had begun as a barely functional prototype was, almost two years later, a core component of our redesigned client and a solid foundation atop which to keep innovating.
It’s a truism that you shouldn’t attempt large rewrites of existing software applications. But like all truisms, it’s only almost always true. Sometimes, when the architecture of an application drifts far enough from how that application is used, prototyping a path towards rewriting the core foundation is actually the best way to achieve your goals.
Now that Unified Grid is live, we’re excited to see what’s next. What else can be built atop a more flexible information architecture? Whatever it is, we know that we’ll be prototyping the path to new, intuitive product experiences well into the future. If that’s something that excites you too, come join us.