

Understanding RAG III: Fusion Retrieval and Reranking
Image by Editor | Midjourney & Canva
Check out the previous articles in this series:
Having previously introduced what is RAG, why it matters in the context of Large Language Models (LLMs), and what does a classic retriever-generator system for RAG look like, the third post in the “Understanding RAG” series examines an upgraded approach to building RAG systems: fusion retrieval.
Before deep diving, it is worth briefly revisiting the basic RAG scheme we explored in part II of this series.
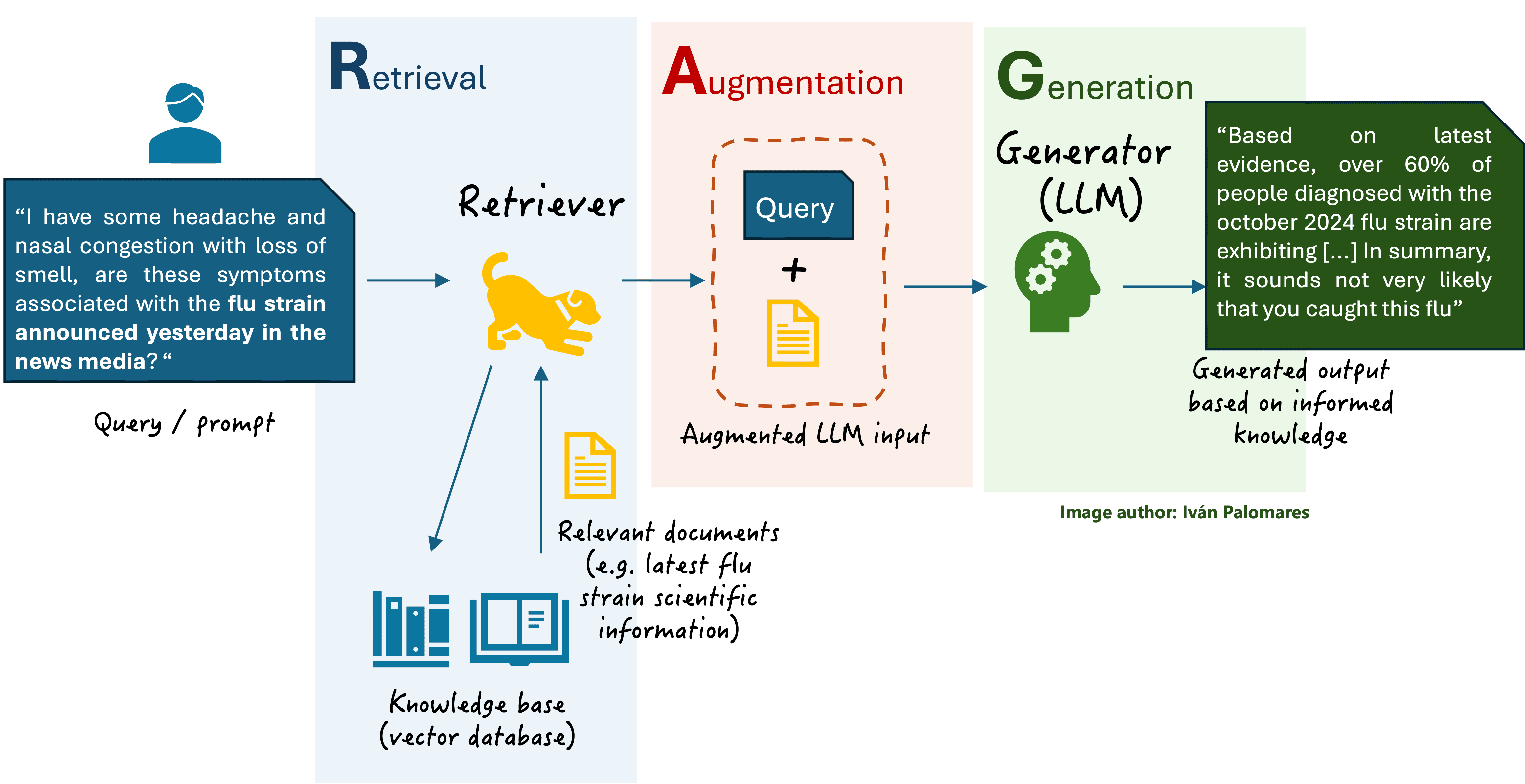
Basic RAG scheme
Fusion Retrieval Explained
Fusion retrieval approaches involve the fusion or aggregation of multiple information flows during the retrieval stage of a RAG system. Recall that during the retrieval phase, the retriever -an information retrieval engine- takes the original user query for the LLM, encodes it into a vector numerical representation, and uses it to search in a vast knowledge base for documents that strongly match the query. After that, the original query is augmented by adding additional context information resulting from the retrieved documents, finally sending the augmented input to the LLM that generates a response.
By applying fusion schemes in the retrieval stage, the context added on top of the original query can become more coherent and contextually relevant, further improving the final response generated by the LLM. Fusion retrieval leverages the knowledge from multiple pulled documents (search results) and combines it into a more meaningful and accurate context. However, the basic RAG scheme we are already familiar with can also retrieve multiple documents from the knowledge base, not necessarily just one. So, what is the difference between the two approaches?
The key difference between classic RAG and fusion retrieval lies in how the multiple retrieved documents are processed and integrated into the final response. In classic RAG, the content in the retrieved documents is simply concatenated or, at most, extractively summarized, and then fed as additional context into the LLM to generate the response. There are no advanced fusion techniques applied. Meanwhile, in fusion retrieval, more specialized mechanisms are used to combine relevant information across multiple documents. This fusion process can occur either in the augmentation stage (retrieval stage) or even in the generation stage.
- Fusion in the augmentation stage consists of applying techniques to reorder, filter, or combine multiple documents before they are passed to the generator. Two examples of this are reranking, where documents are scored and ordered by relevance before being fed into the model alongside the user prompt, and aggregation, where the most relevant pieces of information from each document are merged into a single context. Aggregation is applied through classic information retrieval methods like TF-IDF (Term Frequency – Inverse Document Frequency), operations on embeddings, etc.
- Fusion in the generation stage involves the LLM (the generator) processing each retrieved document independently -including the user prompt- and fusing the information of several processing jobs during the generation of the final response. Broadly speaking, the augmentation stage in RAG becomes part of the generation stage. One common method in this category is Fusion-in-Decoder (FiD), which allows the LLM to process each retrieved document separately and then combine their insights while generating the final response. The FiD approach is described in detail in this paper.
Reranking is one of the simplest yet effective fusion approaches to meaningfully combine information from multiple retrieved sources. The next section briefly explains how it works:
How Reranking Works
In a reranking process, the initial set of documents fetched by the retriever is reordered to improve relevance to the user query, thereby better accommodating the user’s needs and enhancing the overall output quality. The retriever passes the fetched documents to an algorithmic component called a ranker, which re-evaluates the retrieved results based criteria like learned user preferences, and applies a sorting of documents aimed at maximizing the relevance of the results presented to that particular user. Mechanisms like like weighted averaging or other forms of scoring are used to combine and prioritize the documents in the highest positions of the ranking, such that content from documents ranked near the top is more likely to become part of the final, combined context than content from documents ranked at lower positions.
The following diagram illustrates the reranking mechanism:
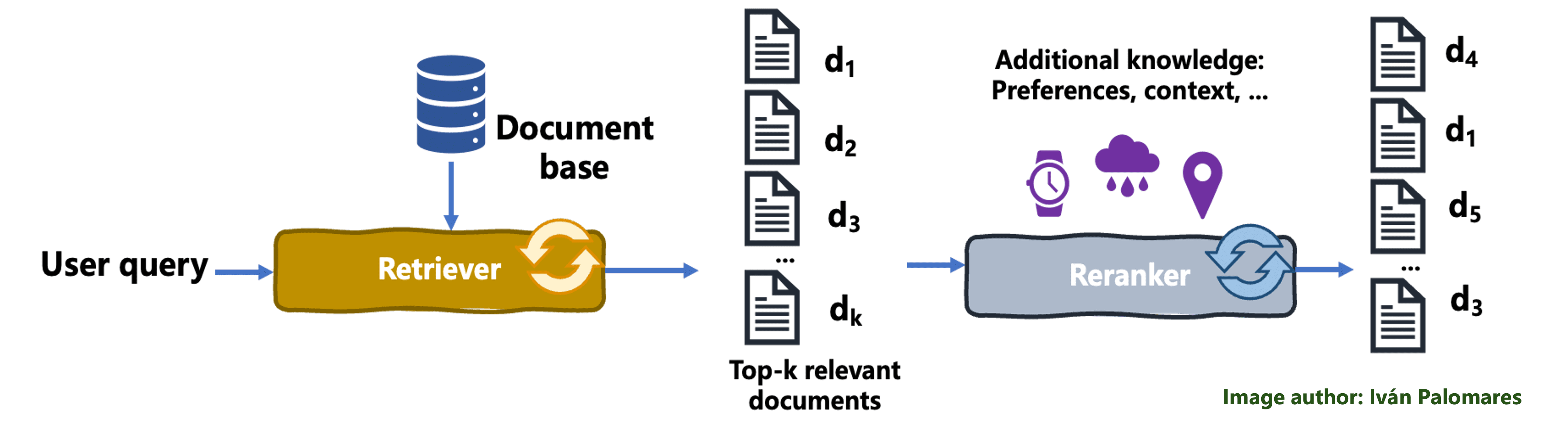
The reranking process
Let’s describe an example to better understand reranking, in the context of tourism in Eastern Asia. Imagine a traveler querying a RAG system for “top destinations for nature lovers in Asia.” An initial retrieval system might return a list of documents including general travel guides, articles on popular Asian cities, and recommendations for natural parks. However, a reranking model, possibly using additional traveler-specific preferences and contextual data (like preferred activities, previously liked activities or previous destinations), can reorder these documents to prioritize the most relevant content to that user. It might highlight serene national parks, lesser-known hiking trails, and eco-friendly tours that might not be at the top of everyone’s list of suggestions, thereby offering results that go “straight to the point” for nature-loving tourists like our target user.
In summary, reranking reorganizes multiple retrieved documents based on additional user relevance criteria to focus the content extraction process in documents ranked first, thereby improving relevance of subsequent generated responses.
About Iván Palomares Carrascosa
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.



