
RLEF: A Reinforcement Learning Approach to Leveraging Execution Feedback in Code Synthesis
Large Language Models (LLMs) generate code aided by Natural Language Processing. There is a growing application of code generation in complex tasks such as software development and testing. Extensive alignment with input is crucial for an adept and bug-free output, but the developers identified it as computationally demanding and time-consuming. Hence, creating a framework for the algorithm to improve itself continuously to provide real-time feedback in the form of error messages or negative points became paramount to address this challenge.
Traditionally, LLMs have trained on supervised learning algorithms employing large labelled datasets. They are inflexible and have generalisation issues, making it difficult for the LLM to adapt to the user environment. A number of samples have to be generated by the algorithm, which increases the computation cost. The execution feedback loop was proposed to tackle this problem, through which the models learned to align their outputs with input requirements by providing feedback iteratively in that particular environment. This mechanism also reduced the number of samples generated. However, the dependency on the execution environment was a disadvantage.
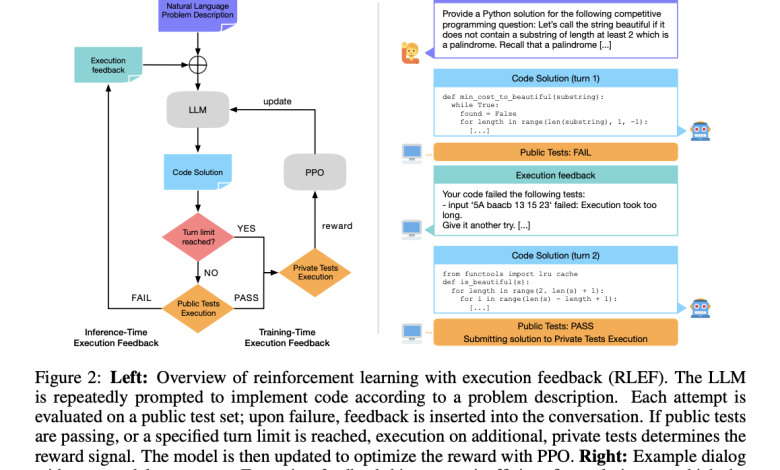
Through this paper, a team of Meta AI researchers introduce a reinforcement learning framework that leverages the code augmentation of the execution feedback loop. The LLM generates a code based on the user’s instructions, evaluates some public test cases, and provides feedback. This process constructs an iterative loop, and the algorithm learns to work to maximise the reward. The innovation of the reinforcement learning framework was enforcing the feedback loop to interact with various environments.
While training the models in RLEF, iterative code refinement continues until either end-point is encountered: All public test cases were successful or a predefined limit of iterations was conducted. For validation, the evaluation is also performed on private test cases, which also helps prevent cases of overfitting. It is also possible to describe this process under the Markov Decision Process (MDP). The reward system is very much defined, and positive reward points are only given when every test case is passed. Of all other cases, there is always a penalty. Before coming up with the final output, the LLM’s behaviour is then fine-tuned using Proximal Policy Optimization (PPO).
The source of code for this experiment was generated during comparative analysis with the CodeContests benchmark. The foregoing outcomes indicated that through the RLEF training, the performance of the models was enhanced when limited to a few sample situations, but the larger samples did not. On older models, the solve rate rises from 4.1 to 12.5 on the valid set and 3.2 to 12.1 on the test set. Before RLEF training, the feedback between the turns did not improve the base models such as GPT-4 or the larger 70B Llama 3.1After RLEF training; the models are much better at enhancing the larger 70B Llama 3.1 in the multi-turn scenarios from the output feedback during execution. It was also observed that models trained with RLEF make more different and accurate code modifications between answers compared to non-RLEF models, which often return erroneous solutions over and over despite obtaining guidance.
In conclusion, Reinforcement Learning with Execution Feedback (RLEF) is the breakthrough for Large Language Models (LLMs) in code generation. Thus, the iterative feedback loop is also flexible for different settings, enhances RLEF, and increases the ability of the models to revise the result based on the current performance much higher. The findings reveal an increase in the model’s effectiveness in processing multi-turn conversations and reducing computational time and error rates. RLEF presents a sound approach to overcome the challenges of supervised learning and helps develop efficient and adaptive coding for software engineering.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!

Afeerah Naseem is a consulting intern at Marktechpost. She is pursuing her B.tech from the Indian Institute of Technology(IIT), Kharagpur. She is passionate about Data Science and fascinated by the role of artificial intelligence in solving real-world problems. She loves discovering new technologies and exploring how they can make everyday tasks easier and more efficient.



