I am very excited for the release of Python 3.13.
I probably haven’t been this excited for a Python release since f-strings were added in Python 3.6.
I’d like to share a few of my favorite features from Python 3.13, and I suspect that at least a few of these will become your favorites as well.
Important but not my favorite
First, I’d like to note that I’m not going to talk about the experimental free-threaded mode, the experimental just-in-time compilation option, or many other features that don’t affect most Python developers today.
Instead, let’s focus on some of the more fun things.
The New Python REPL
My favorite feature by far is the new Python REPL.
Block-level editing in REPL
Have you ever made a mistake while typing a block of code in the Python REPL?
>>> import csv
>>> from collections import Counter
>>> with open("penguins_small.csv") as penguins_file:
... csv_reader = csv.DictReader(penguins_file)
... species_counts = Counter(
... row['species']
... for row in reader
... )
...
Traceback (most recent call last):
File "<python-input-95>", line 5, in <module>
for row in reader
^^^^^^
NameError: name 'reader' is not defined
The old REPL had line-based history, so fixing that mistake required hitting the Up arrow over and over.
This was very tedious.
In Python 3.13, we don’t have to do all of this work.
Instead, the new Python 3.13 REPL supports block-level history and block-level editing!
So when you make a mistake in a block of code, you just hit the Up arrow, navigate to where the mistake is, fix the mistake, and then hit Enter:
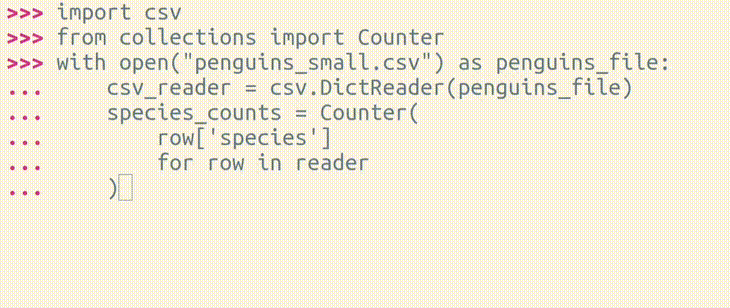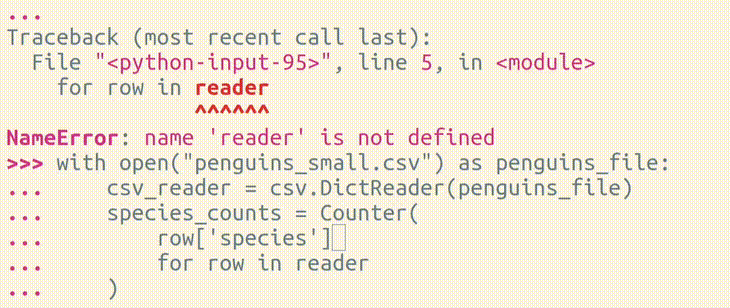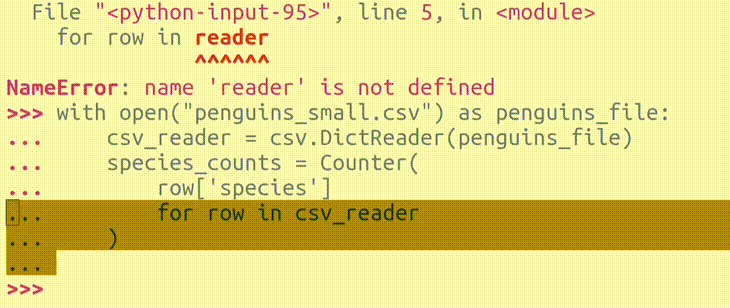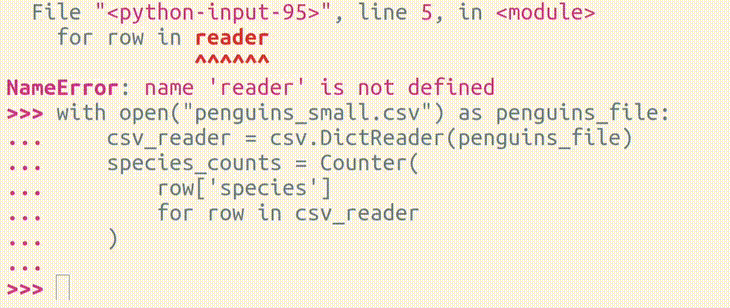
Block-level editing is definitely my favorite improvement in the new Python REPL.
Paste code seamlessly in the new REPL
Have you ever tried pasting a class into the Python REPL?
class Thing:
"""An example class."""
def __init__(self, name):
self.name = name
def __repr__(self):
return f"Thing({self.name!r})"
You probably found that as soon as the REPL encountered a blank line, it assumed that it should end the current code block:
>>> class Thing:
... """An example class."""
...
>>> def __init__(self, name):
File "<stdin>", line 1
def __init__(self, name):
IndentationError: unexpected indent
>>> self.name = name
File "<stdin>", line 1
self.name = name
IndentationError: unexpected indent
>>>
>>> def __repr__(self):
File "<stdin>", line 1
def __repr__(self):
IndentationError: unexpected indent
>>> return f"Thing({self.name!r}\
File "<stdin>", line 1
return f"Thing({self.name!r}\
IndentationError: unexpected indent
The easiest way to fix this was to remove all blank lines from your code, which is a really annoying thing to do just for the sake of pasting code into the REPL:
>>> class Thing:
... """An example class."""
... def __init__(self, name):
... self.name = name
... def __repr__(self):
... return f"Thing({self.name!r})
"
...
The new REPL now knows when you’re pasting code, and it does exactly what you would hope it would do!
>>> class Thing:
... """An example class."""
...
... def __init__(self, name):
... self.name = name
...
... def __repr__(self):
... return f"Thing({self.name!r})"
...
It just works!
History mode in the REPL
In addition to block-level editing and the ability to paste arbitrary code, the new REPL now has a history mode.
Have you ever used the REPL to try something out, and then you decided you wanted to copy-paste that code into a Python file?
>>> import csv
>>> from collections import Counter
>>> with open("penguins_small.csv") as penguins_file:
... csv_reader = csv.DictReader(penguins_file)
... species_counts = Counter(
... row['species']
... for row in csv_reader
... )
...
When you copy-paste from the REPL, you’ll get these prompts pasted as well:
>>> import csv
>>> from collections import Counter
>>> with open("penguins_small.csv") as penguins_file:
... csv_reader = csv.DictReader(penguins_file)
... species_counts = Counter(
... row['species']
... for row in csv_reader
... )
...
Those three greater than signs (>>>) and three dots (...) will come along with your code, which won’t be valid Python code.
This is a little bit annoying.
Fortunately, the new Python REPL has a history mode that you can trigger by hitting the F2 key.
History mode doesn’t show those prompts:
import csv
from collections import Counter
with open("penguins_small.csv") as penguins_file:
csv_reader = csv.DictReader(penguins_file)
species_counts = Counter(
row['species']
for row in csv_reader
)
/home/trey/.python_history line 1/8 (END) (press h for help or q to quit)
So you can paste your code just as you wrote it originally in the REPL.
Other improvements in the new REPL
Those are all of my favorite features in the new REPL, but there are other little niceties as well.
For example:
- The prompt is now colorized and so are tracebacks
- When working in a block of code, you’ll be auto-indented when moving to the next line
- Hitting the Tab key now inserts 4 spaces (instead of inserting a tab character)
- If you type
exit, the REPL won’t tell you to run theexit()function… it’ll just exit!
So the new REPL in Python 3.13 on its own is a huge improvement
But it’s not the only new feature.
Git-friendly virtual environments
Virtual environments also changed in a very subtle, but very handy way, for those of us using Git to version-control our code.
In previous Python versions, whenever you created a new virtual environment within a git repository, you would see that virtual environment’s directory listed whenever you ran a git status command:
~/project1 $ python3.12 -m venv .venv
~/project1 $ git status
On branch main
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
.venv/
nothing added to commit but untracked files present (use "git add" to track)
To fix this, you needed to manually add virtual environment directories to your project’s .gitignore file:
~/project1 $ echo ".venv" >> .gitignore
~/project1 $ git status
On branch main
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
nothing added to commit but untracked files present (use "git add" to track)
With Python 3.13, you’ll never need to git-ignore a virtual environment ever again!
After you’ve made a virtual environment with Python 3.13, Git won’t see it:
~/project2 $ python3.13 -m venv .venv
~/project2 $ git status
On branch main
No commits yet
nothing to commit (create/copy files and use "git add" to track)
This happens because the new virtual environment has its own .gitignore file that ignores itself:
~/project2 $ cat .venv/.gitignore
# Created by venv; see https://docs.python.org/3/library/venv.html
*
As someone who teaches virtual environments along with Django and Git, I love this change.
This will allow me to remove an important, but confusing step, in my curriculum, at least for folks on the latest version of Python.
Python Debugger improvements
The Python Debugger (PDB) also got two big improvements in Python 3.13.
Breakpoints start on breakpoint() line
If you’ve ever tried to set a breakpoint at the end of a code block, you may have noticed that PDB starts up just after the code block exits.
For example, here we have a function:
from pathlib import Path
import sys
def total_line_count(paths):
line_count = 0
for path in paths:
line_count += len(Path(path).read_text().splitlines())
return line_count
It’s currently failing when we call it with specific files:
>>> total_line_count(["file1.txt", "file2.txt", "file3.txt"])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/trey/total_line_count.py", line 7, in total_line_count
line_count += len(Path(path).read_text().splitlines())
^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/pathlib.py", line 1029, in
read_text
return f.read()
^^^^^^^^
File "<frozen codecs>", line 322, in decode
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x93 in position 19: invalid sta
rt byte
Ultimately, we may want to update this code to provide more information about which file it’s failing on.
But for now, let’s just catch the exception, and then set a breakpoint so we can see which file it’s failing on:
from pathlib import Path
import sys
def total_line_count(paths):
line_count = 0
for path in paths:
try:
line_count += len(Path(path).read_text().splitlines())
except Exception as e:
breakpoint()
return line_count
In Python 3.12, when we set a breakpoint at the end of an except block, PDB starts up after the except block:
>>> total_line_count(["file1.txt", "file2.txt", "file3.txt"])
> /home/trey/total_line_count.py(6)total_line_count()
-> for path in paths:
(Pdb)
This means the exception object has disappeared by the time the breakpoint is hit!
(Pdb) e
*** NameError: name 'e' is not defined
If we look at which line of code we’re on, we’re at the top of our for loop:
(Pdb) l
1 from pathlib import Path
2 import sys
3
4 def total_line_count(paths):
5 line_count = 0
6 -> for path in paths:
7 try:
8 line_count += len(Path(path).read_text().splitlines())
9 except Exception as e:
10 breakpoint()
11 return line_count
Because this breakpoint isn’t actually set inside the block, it’s set after the block.
If we run this same code in Python 3.13, PDB will now start up on the same line as the breakpoint:
>>> total_line_count(["file1.txt", "file2.txt", "file3.txt"])
> /home/trey/total_line_count.py(10)total_line_count()
-> breakpoint()
(Pdb)
So adding a breakpoint to the end of a block of code works the way you would expect it to.
We’re able to take a look at the Exception object without any problem.
(Pdb) e
UnicodeDecodeError('utf-8', b'I said \x93hello\x94!', 7, 8, 'invalid start byte')
That’s the first big improvement to the Python debugger.
The second one is even better!
Easier Python statements in PDB
Historically, any line in the Python debugger prompt that started with a PDB command would usually trigger the PDB command, instead of PDB interpreting the line as Python code.
So attempting to use the help function like this didn’t work:
(Pdb) help(breakpoint)
*** No help for '(breakpoint)'
(Pdb)
But now, if the command looks like Python code, pdb will run it as Python code!
That means that the built-in help function, the list function, the next function, and various other lines of Python code will work as expected:
(Pdb) help(breakpoint)
Help on built-in function breakpoint in module builtins:
breakpoint(*args, **kws)
Call sys.breakpointhook(*args, **kws). sys.breakpointhook() must accept
whatever arguments are passed.
By default, this drops you into the pdb debugger.
This might seem like a small improvement, but wrestling with PDB when it thinks I wanted a PDB command instead of a Python statement is really frustrating, especially because when I’m in PDB I’m usually already frustrated because something is broken with my code and I don’t why.
Try out Python 3.13
If you’re excited about the new Python REPL, the fact that virtual environments are git-ignored by default, or the new Python debugger improvements, go install Python 3.13 and try it out!
For the full list of what’s new, check out the Python documentation.