
OpenAI Researchers Introduce MLE-bench: A New Benchmark for Measuring How Well AI Agents Perform at Machine Learning Engineering
Machine Learning (ML) models have shown promising results in various coding tasks, but there remains a gap in effectively benchmarking AI agents’ capabilities in ML engineering. Existing coding benchmarks primarily evaluate isolated coding skills without holistically measuring the ability to perform complex ML tasks, such as data preparation, model training, and debugging.
OpenAI Researchers Introduce MLE-bench
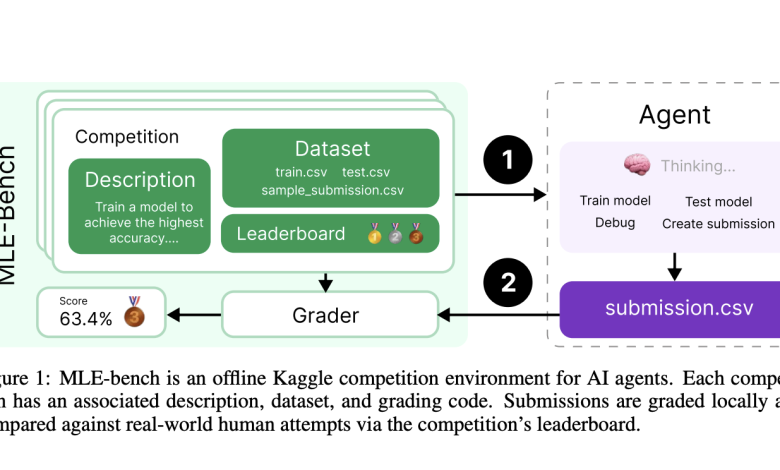
To address this gap, OpenAI researchers have developed MLE-bench, a comprehensive benchmark that evaluates AI agents on a wide array of ML engineering challenges inspired by real-world scenarios. MLE-bench is a novel benchmark aimed at evaluating how well AI agents can perform end-to-end machine learning engineering. It is constructed using a collection of 75 ML engineering competitions sourced from Kaggle. These competitions encompass diverse domains such as natural language processing, computer vision, and signal processing. The competitions are carefully curated to assess key ML skills, including training models, data preprocessing, running experiments, and submitting results for evaluation. To provide an accurate baseline, human performance metrics are gathered from publicly available Kaggle leaderboards, enabling comparisons between the capabilities of AI agents and expert human participants.
Structure and Details of MLE-bench
MLE-bench features several design aspects to assess ML engineering effectively. Each of the 75 Kaggle competition tasks is representative of practical engineering challenges, making the benchmark both rigorous and realistic. Each Kaggle competition in MLE-bench consists of a problem description, dataset, local evaluation tools, and grading code used to assess the agent’s performance. To ensure comparability, each competition’s dataset is split into training and testing sets, often redesigned to avoid any overlap or contamination issues. Submissions are graded against human attempts using competition leaderboards, and agents receive medals (bronze, silver, gold) based on their performance relative to human benchmarks. The grading mechanism relies on standard evaluation metrics, such as the area under the receiver operating characteristic (AUROC), mean squared error, and other domain-specific loss functions, providing a fair comparison to Kaggle participants. AI agents, such as OpenAI’s o1-preview model combined with AIDE scaffolding, have been tested on these tasks, achieving results comparable to a Kaggle bronze medal in 16.9% of competitions. Performance significantly improved with repeated attempts, indicating that while agents can follow well-known approaches, they struggle to recover from initial mistakes or optimize effectively without multiple iterations. This highlights both the potential and the limitations of current AI systems in performing complex ML engineering tasks.
Experimental Results and Performance Analysis
The evaluation of different scaffolds and AI models on MLE-bench reveals interesting findings. OpenAI’s o1-preview model with AIDE scaffolding emerged as the best-performing setup, achieving medals in 16.9% of the competitions, and performance significantly improved with multiple attempts. Agents often performed better when they could iterate on their solutions, highlighting the importance of multiple passes in addressing challenges and optimizing solutions. When given additional resources, such as increased compute time and hardware, agents showed better results, emphasizing the impact of resource allocation. For example, the performance of GPT-4o doubled from 8.7% when given 24 hours to 11.8% when given 100 hours per competition. Furthermore, the experiments revealed that scaling up the number of attempts (pass@k) had a significant impact on the success rate, with pass@6 achieving nearly double the performance of pass@1. Additionally, experiments on scaling resources and agent scaffolding demonstrate the variability in performance based on resource availability and optimization strategies. Specifically, agents like o1-preview exhibited notable improvements in competitions requiring extensive model training and hyperparameter tuning when given longer runtimes or better hardware configurations. This evaluation provides valuable insights into the strengths and weaknesses of current AI agents, particularly in debugging, handling complex datasets, and effectively utilizing available resources.

Conclusion and Future Directions
MLE-bench represents a significant step forward in evaluating the ML engineering capabilities of AI agents, focusing on holistic, end-to-end performance metrics rather than isolated coding skills. The benchmark provides a robust framework for assessing various facets of ML engineering, including data preprocessing, model training, hyperparameter tuning, and debugging, which are essential for real-world ML applications. It aims to facilitate further research into understanding the potential and limitations of AI agents in performing practical ML engineering tasks autonomously. By open-sourcing MLE-bench, OpenAI hopes to encourage collaboration, allowing researchers and developers to contribute new tasks, improve existing benchmarks, and explore innovative scaffolding techniques. This collaborative effort is expected to accelerate progress in the field, ultimately contributing to safer and more reliable deployment of advanced AI systems. Additionally, MLE-bench serves as a valuable tool for identifying key areas where AI agents require further development, providing a clear direction for future research efforts in enhancing the capabilities of AI-driven ML engineering.
Setup
Some MLE-bench competition data is stored using Git-LFS. Once you have downloaded and installed LFS, run:
git lfs fetch --all
git lfs pullYou can install mlebench With pip:
pip install -e .Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Data Retrieval Conference (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.



