
MIBench: A Comprehensive AI Benchmark for Model Inversion Attack and Defense
A Model Inversion (MI) attack is a type of privacy attack on machine learning and deep learning models, where an attacker tries to invert the model’s outputs to recreate privacy-sensitive training data that was used during training including the leakage of private images in face recognition models, sensitive health details in medical data, financial information such as transaction records and account balances, and personal preferences and social connections in social media data, etc. raising widespread concerns about privacy threats of Deep Neural Networks (DNNs). Unfortunately, as MI attacks have become advanced, there hasn’t been a complete and reliable way to test and compare these attacks, making it difficult to evaluate the security of the model. This deficiency leads to inadequate comparisons between different attack methods and inconsistent experimental setups. Additionally, the absence of unified experimental protocols results in a fragmented landscape where there is less validity and fairness in the comparative studies.
Until now it was very hard to find any such benchmark that could measure a model’s potential to defend itself against such threats. Although to defend against MI attacks, most existing methods can be categorized into two types: model output processing and robust model training. Model output processing refers to reducing the private information carried in the victim model’s output to promote privacy. Yang et al. propose to train an autoencoder to purify the output vector by decreasing its degree of dispersion. Wen et al. apply adversarial noises to the model output and confuse the attackers. Ye et al. leverage a differential privacy mechanism to divide the output vector into multiple sub-ranges. Robust model training refers to incorporating defense strategies during the training process. MID Wang et al. penalizes the mutual information between model inputs and outputs in the training loss, thus reducing the redundant information carried in the model output that may be abused by the attackers.
Existing MI attacks and defenses lack a comprehensive, aligned, and reliable benchmark, resulting in inadequate comparisons and inconsistent experimental setups. Thus researchers introduced a benchmark to measure the potential and determine the vulnerability of the model against such Model Inversion attacks.
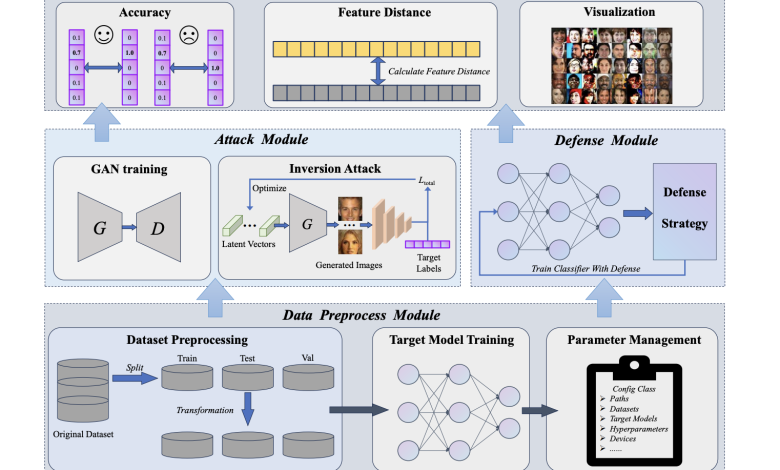
To alleviate these problems, researchers from the UniHarbin Institute of Technology (Shenzhen) and Tsinghua University introduced the first benchmark in the MI field, named MIBench. For building an extensible modular-based toolbox, they disassemble the pipeline of MI attacks and defenses into four main modules, each designated for data preprocessing, attack methods, defense strategies, and evaluation, enhancing this merged framework’s extensibility. The proposed MIBench has encompassed a total of 16 methods comprising 11 attack methods and 4 defense strategies, coupled with 9 prevalent evaluation protocols to adequately measure the comprehensive performance of individual MI methods and with a focus on Generative Adversarial Network (GAN)-based MI attacks. Based on the accessibility to the target model’s parameters, researchers categorized MI attacks into white-box and black-box attacks. White-box attacks can entail full knowledge of the target model, enabling the computation of gradients for performing backpropagation, while black-box attacks are constrained to merely obtaining the prediction confidence vectors of the target model. The MIBench benchmark includes 8 white-box attack methods and 4 black-box attack methods.
Overview of the basic structure of modular-based toolbox for MIB benchmark
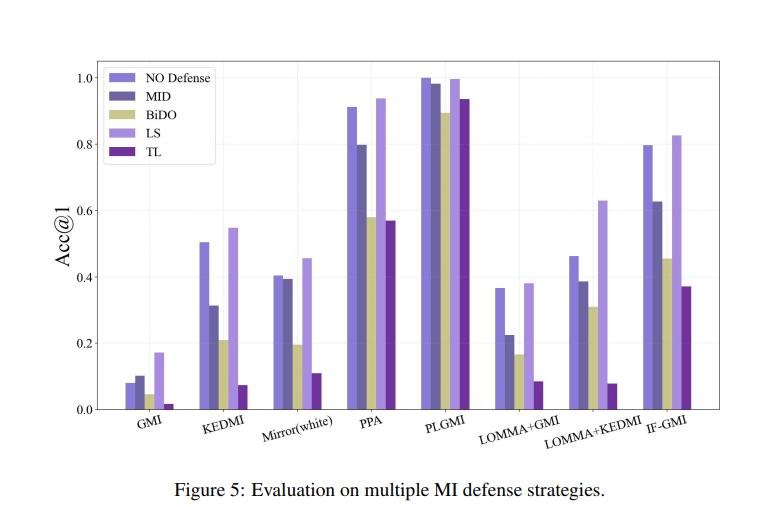
The researchers tested MI attack strategies on two models (IR-152 for low and ResNet-152 for high resolution) using public and private datasets. Parameters like Accuracy, Feature Distance, and FID were used to compare white-box and black-box attacks to validate the method. Strong methods like PLGMI and LOKT showed high accuracy, while PPA and C2FMI produced more realistic images, especially in higher resolution. It was observed by the researchers that the effectiveness of MI attacks increased with the model’s predictive power. Current defense strategies were not fully effective, highlighting the need for better methods to protect privacy without reducing model accuracy.

In conclusion, the reproducible benchmark will facilitate the further development of the MI field and bring more innovative explorations in the subsequent study. In the future, MIBench could provide a unified, practical and extensible toolbox and is widely utilized by researchers in the field to rigorously test and compare their novel methods, ensuring equitable evaluations and thereby propelling further advancements in future development.
However, a possible negative impact of the MIB benchmark is that harmful users could use the attack methods to recreate private data from public systems. To address this, data users need to apply strong and reliable defense strategies and methods. Additionally, setting up access controls and limiting how often each user can access the data is important for building responsible AI systems, and reducing potential conflicts with people’s private data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.



