
Llama-3-Nanda-10B-Chat: A 10B-Parameter Open Generative Large Language Model for Hindi with Cutting-Edge NLP Capabilities and Optimized Tokenization
Natural Language Processing (NLP) focuses on building computational models to interpret and generate human language. With advancements in transformer-based models, large language models (LLMs) have shown impressive English NLP capabilities, enabling applications ranging from text summarization and sentiment analysis to complex reasoning tasks. However, NLP for Hindi still needs to be improved, mainly due to a need for high-quality Hindi data and language-specific models. With Hindi being the fourth most spoken language globally, serving over 572 million speakers, a dedicated, high-performance Hindi-centric model has significant potential for real-world applications.
A crucial challenge in developing NLP tools for Hindi is the limited data available compared to English, which has extensive corpora exceeding 15 trillion tokens. Due to this scarcity, multilingual models like Llama-2 and Falcon are commonly used for Hindi, but they need help with performance issues as they spread resources across many languages. Despite covering over 50 languages, such models underperform in Hindi-specific tasks because they cannot focus enough on Hindi without affecting other languages. This limits the accuracy and fluency of these models in Hindi, hampering the development of applications designed for Hindi-speaking audiences. The research community has thus identified an urgent need for a model exclusively tailored to Hindi, using large-scale, high-quality Hindi datasets and optimized model architecture.
Existing Hindi NLP models often rely on general-purpose multilingual language models with limited Hindi pretraining data. For instance, models like Llama-2, which use byte-pair encoding tokenizers, segment non-English words into multiple subwords, creating inefficiencies in processing Hindi. While these models perform reasonably well in English, they need help with Hindi due to token imbalances, which inflate processing costs and reduce accuracy. Multilingual LLMs also frequently face the “curse of multilinguality,” where performance deteriorates as they attempt to support a wide range of languages. Hence, a more focused approach that addresses the unique challenges of Hindi processing is essential to enhance performance and applicability.
Researchers Mohamed bin Zayed University of Artificial Intelligence UAE, Inception UAE, and Cerebras Systems introduced Llama-3-Nanda-10B-Chat (Nanda), a Hindi-centric, instruction-tuned LLM with 10 billion parameters. Developed from the Llama-3-8B model, Nanda incorporates extensive pretraining on 65 billion Hindi tokens and selectively integrates English for bilingual support. Unlike broader multilingual models, Nanda dedicates its architecture primarily to Hindi, combining a Hindi-English dataset mix in a 1:1 ratio during training to balance linguistic capabilities. Through continuous pretraining, this model refines its proficiency in Hindi while maintaining effectiveness in English, making it a strong candidate for applications requiring bilingual NLP.
The model’s architecture is based on a decoder-only design with 40 transformer blocks, increasing from the standard 32 in Llama-3. This expansion enables efficient language adaptation, reducing training overhead compared to starting from scratch. The training infrastructure utilized the Condor Galaxy 2 AI supercomputer, running 16 CS-2 systems to handle the extensive data requirements. The researchers used AdamW optimization with a learning rate of 1.5e-5 and batch sizes of 4 million, optimizing the model through careful tuning of hyperparameters. To maximize data utilization, Nanda’s training included sequences of up to 8,192 tokens, with each sequence marking document boundaries, thereby minimizing cross-document interference and ensuring cohesive language processing.
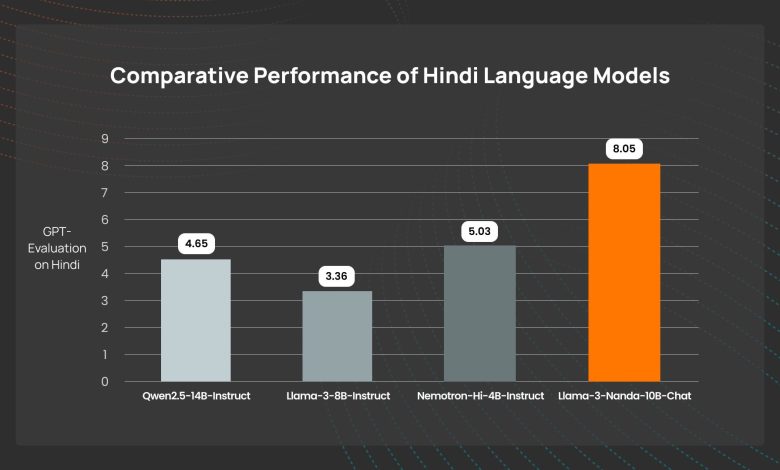
Nanda’s evaluations showed outstanding results in both Hindi and English benchmarks, setting a new standard for Hindi LLMs. On Hindi-specific benchmarks like MMLU, HellaSwag, ARC-Easy, and TruthfulQA, Nanda scored an average of 47.88 in zero-shot tasks, outperforming competitors such as AryaBhatta-Gemma and Nemotron. The model remained competitive in English evaluations, achieving a score of 59.45, which is only slightly lower than dedicated English models like Qwen2.5-14B. These results underscore Nanda’s adaptability, demonstrating how a Hindi-centric model can perform effectively across languages without sacrificing core capabilities in Hindi.

The key takeaways from the research are as follows:
- Data Curation: Nanda was pretrained on a vast Hindi dataset of 65 billion tokens, derived from high-quality sources like Wikipedia, news articles, and books, alongside 21.5 million English tokens for bilingual support. These data sources ensure the model has depth in Hindi and bilingual flexibility.
- Efficient Architecture: With 40 transformer blocks, Nanda’s architecture is optimized for Hindi language processing. Leveraging block expansion for better language adaptation can outperform multilingual models on Hindi tasks.
- Performance on Benchmarks: Nanda achieved 47.88 on Hindi zero-shot tasks and 59.45 on English, demonstrating that its Hindi specialization does not compromise its bilingual capabilities.
- Safety and Instruction Tuning: With a robust safety-focused dataset covering over 50K attack prompts, Nanda is equipped to handle sensitive content in Hindi, reducing the risk of generating biased or harmful content.
- Tokenization Efficiency: By developing a Hindi-English balanced tokenizer with low fertility (1.19 for Hindi), Nanda achieved efficient processing, reducing tokenization costs and enhancing response speed compared to generic multilingual tokenizers.

In conclusion, Nanda represents a significant advancement in Hindi NLP, bridging critical gaps in language processing and providing a specialized model that excels in both Hindi and English tasks. By focusing on Hindi-centric data and adopting optimized architectures, Nanda addresses the longstanding challenges in Hindi NLP, setting a new standard for bilingual language applications. This model offers researchers, developers, and businesses a powerful tool to expand Hindi-language capabilities, supporting a growing demand for inclusive and culturally sensitive AI applications.
Check out the Model on Hugging Face and Paper.. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.



