Feature Caching for Recommender Systems w/ Cachelib | by Pinterest Engineering | Pinterest Engineering Blog | Sep, 2024
Li Tang; Sr. Software Engineer | Saurabh Vishwas Joshi; Sr. Staff Software Engineer | Zhiyuan Zhang; Sr. Manager, Engineering |
At Pinterest, we operate a large-scale online machine learning inference system, where feature caching plays a critical role to achieve optimal efficiency. In this blog post, we will discuss our decision to adopt Cachelib project by Meta Open Source (“Cachelib”) and how we have built a high-throughput, flexible feature cache by leveraging and expanding upon the capabilities of Cachelib.
Recommender systems are fundamental to Pinterest’s mission to inspire users to create a life they love. At a high level, our recommender models predict user and content interactions based on ML features associated with each user and Pin.
These ML features are stored in an in-house feature store as key-value datasets: the keys are identifiers for various entities such as pins, boards, links, and users, while the values follow a unified feature representation, defined in various schema formats including Thrift project by Meta Open Source and Flatbuffers project by Google Open Source.
A primary challenge involves fetching ML features to support model inference, which occurs millions of times per second. To optimize for cost and latency, we extensively utilize cache systems to lighten the load on the feature store.
Before adopting Cachelib, we had two in-process cache options within our C++ services:
- LevelDB (project by Google Open Source)-based ephemeral in-memory cache
- Block-based RocksDB (project by Meta Open Source) persistent LRU cache that utilizes SSDs
However, as our system scaled, we encountered increasing operational and scalability challenges with these options. This led us to seek a new caching solution that could better meet our needs.
CacheLib is a general-purpose in-process caching engine open-sourced and maintained by Meta Open Source. Besides being battle tested at Meta’s scale, we found it also meets our specific demands in several key areas:
- Easy Integration with C++ Services: To minimize latency and cost, using a local, in-process cache is essential to reduce RPC overhead, especially the cost associated with transferring cached features between processes. Cachelib seamlessly integrates into our C++ systems as a library. Particularly, its zero-copy reads significantly reduce CPU and memory usage, which is crucial for a high-throughput application like ours.
- Efficient Memory Management and Eviction Policies: Cachelib offers a broad range of configurable options for cache pool management and eviction policies. This flexibility has helped us minimize memory usage and fragmentation, tailored to our traffic patterns.
- Persistent Cache: The ability to retain cache state across service restarts prevents read spikes to the feature store during system deployments, which could otherwise lead to feature fetching failures and degraded inference results.
- Hybrid Caching: Utilizing both memory and SSDs has dramatically increased our cache capacity, particularly for non-latency-sensitive use cases. The increased cache capacity has not only improved the hit rate but also enabled us to experiment with different caching architectures, which will be described in later sections.
While Cachelib provides an efficient and reliable cache implementation, its basic key-value interface did not fully meet all our needs in recommender systems. A typical ranking model utilizes hundreds of different kinds of features associated with various entities. For instance, a model might predict the likelihood of a Pinner engaging with a Pin using both Pinner-specific features and Pin-specific features. Using Cachelib’s standard key-value interface, we’d have to store all features under a single key (either Pinner ID or Pin ID), grouped together as one value.
Ideally we want more flexibility:
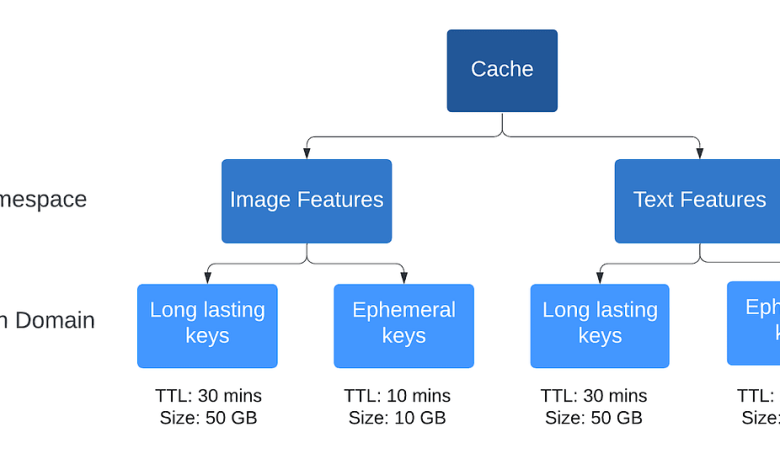
- Segment Features into Different Cache Pools: This allows us to configure the Time to Live (TTL) and pool size independently based on the features’ size distribution, read patterns, and timeliness.
- Establish Different Tiers of Cache Pools: For the same type of feature, we set up different “tiers” of cache pools to distinguish between long-lasting and ephemeral keys.
To achieve these objectives, we enhanced the Cachelib system by adding two additional levels of abstraction on top of the key-value interface:
- Namespace: A separate cache with its own key space, used to store groups of features related to a specific entity. For example, all features derived from a Pin’s text are stored in one namespace, while visual features are stored in another.
- Eviction Domains: Individual cache pools within a namespace, each configured with its own TTL and pool size. A namespace can contain multiple eviction domains.
Cache operations now involve pairs of (namespace, key) because the same key may appear across multiple namespaces. Within a namespace, the key is queried across all eviction domains, with cache writes and evictions managed separately for each domain based on its specific eviction policy.
An example setup can be illustrated as follows:
Our recommender system heavily relies on a caching system to deliver ML features effectively. The placement of the cache within our system is crucial. As our ML inference platform transitioned from CPU to GPU serving, our system architecture evolved accordingly. Below, we describe three different cache architectures and their rationales:
Sharded DRAM Cache
Our initial setup follows a root-leaf architecture:
- The cache key space is split into virtual shards based on hashing. These virtual shards (replicas) are managed and allocated to the leaf nodes by Apache Helix project by Apache Software Foundation.
- Root nodes receive ranking requests with large batches of candidate items. These items are regrouped by their key hashes and redirected to corresponding leaf nodes.
- The main benefit of this architecture is its horizontal scalability: we can always add more leaf nodes/shards, allowing each to handle a smaller key space and thus increasing the overall cache hit rate given a fixed amount of memory.
Single Node Hybrid DRAM + NVM Cache
As our online ML inference workload gradually shifted from CPU to GPU, optimizing GPU throughput became a priority. The ideal GPU workload prefers larger batches of items, conflicting with the root-leaf architecture that splits requests into smaller batches. We attempted to overcome this by dynamically batching requests, but we were unable to merge many small batches into larger ones effectively. This was particularly a challenge for low QPS or experimental models, which affected the overall GPU efficiency.
To address this, we experimented removing the root layers, allowing each ranking node to manage the entire cache key space. This change led to a drop in cache hit rates, higher latency from cache misses and more remote feature fetches. However, removing the scatter-gather step of the root layer and the increased GPU utilization offset these issues and improved latency.
To mitigate the impact of cache misses, we enabled Cachelib’s HybridCache, which utilizes NVM like local SSDs. This significantly increased cache capacity on each node and reduced the infrastructure costs associated with remote lookups from our Feature Stores. Furthermore, to improve tail latency, we implemented speculative lookup, where the ranker node fetches from the Feature Store after a certain timeout if the SSD read is not completed, regardless of whether it’s a miss.
Separate Cache and Inference Nodes
When we first designed our ML inference system, one of the initial decisions was to colocate feature caching and model inference. At that time, most models were less resource-intensive compared to today’s models but required a large amount of features, making an RPC to fetch features a significant overhead. However, as models grew larger and our system transitioned to GPU-based inference, the bottleneck shifted from IO data transfer to GPU compute capabilities.
To address this, we explored separating data fetching/caching and inference across different nodes. This change allowed us to scale feature caching and inference independently:
- Horizontal Scaling: We can now resize our CPU and GPU clusters based on traffic and model size. This enhances our flexibility to scale the system and reduces infrastructure costs.
- Vertical Scaling: We utilize instances with powerful CPUs and substantial memory for data caching. This significantly increases cache capacity and improves cache hit rates compared to our previous setup. The main obstacle here is that each Cachelib instance is restricted to a maximum of 256GB. To overcome this limitation, we create multiple cache instances with the same size and pool configuration. During cache Put and Get operations, we hash the cache key to determine which cache instance is responsible for handling the cache Put and Get operations.
Although this new setup introduces an additional RPC for inference, the end-to-end latency and overall costs have improved. This improvement is due to the higher cache hit rate and the elimination of the CPU bottleneck on GPU nodes.
Below, we compare the cost of separating CPU and GPU nodes vs solely utilizing GPU nodes with colocated cache for our representative ranking use-cases.

Hourly cost is based on AWS public pricing.
Persistent Cache for Service Restart
In-process local caches pose an operational challenge when restarting or deploying a service. When the service process restarts, all in memory data is lost, and the cache needs to be repopulated. Our system requires a high cache hit rate, and warming up the cache sufficiently can take a significant amount of time, ranging from 10 minutes to an hour. During this process, more read requests pass through the cache to the downstream feature store, which is often rate-limited, resulting in decreased system performance and quality.
This challenge is addressed by utilizing Cachelib’s persistent cache, which allows the cache to be restored after a process restart. With persistent caching, our service can restart without negatively impacting the cache hit rate, making our system deployment faster and safer to operate.
Our clusters serve user-facing traffic, which exhibits consistent traffic patterns throughout the day and week. To save infrastructure costs, we automatically scale the system capacity up and down based on the workload. However, this poses a challenge because newly launched nodes start with a cold cache. This issue is particularly severe in clusters with thousands of nodes, where a single scale-up step can add hundreds to thousands of nodes.
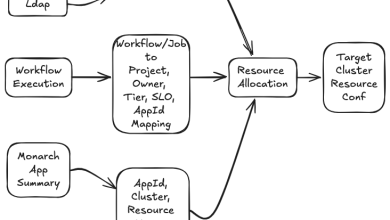
To mitigate the cold cache issue, we implemented a pipeline to warm up the cold cache on new nodes before they start serving traffic. The pipeline consists of the following steps:
1. A group of warm hosts logs feature requests in a 10-minute time window to their local disk. This snapshot of logged requests is then uploaded to S3.
2. When new nodes boot up, they use a local traffic simulator to replay the snapshotted requests from S3 at a slower rate that the feature store can handle.
3. Once the replay completes, the cache is considered warmed up, and the host joins the serverset for serving live traffic.
It’s worth noting that after we implemented our pipeline, Cachelib introduced cross host cache warmup, which can restore the cache using snapshots from a remote node. Although this feature can also mitigate the cold cache issue, we opted to continue using our method because snapshot restoration takes longer than traffic replay. Some of our features are real-time and have short TTLs, so the time required to restore cache snapshots would render them obsolete.
We ran a micro benchmark to compare CacheLib’s single-thread Get/Put performance against the other two cache implementations on synthetic data, with data sizes in accordance with our typical use-case payloads.
The benchmark is conducted by synchronously running cache.put or cache.get with the same key and value 10,000 times in a single thread on a c5.18xl AWS instance and measuring the average latency.

We adopted CacheLib as the local feature cache for Pinterest’s online ML inference systems, replacing our previous caching implementations. Cachelib’s efficiency and rich features such as cache pool management, eviction policies and persistent cache allowed us to meet our the cost and latency requirement, while maintaining flexibility in supporting the various ML feature schema demands. It’s also proven to be a reliable library, seamlessly operating across thousands of nodes with millions of QPS to our systems. By leveraging Cachelib’s hybrid cache capabilities, we were able to adapt our system architecture several times in response to the evolving requirements of data locality driven by GPU utilization.
Zhanyong Wan, Bo Liu, Jian Wang, Nazanin Farahpour, Howard Nguyen, Sihan Wang, Lianghong Xu, Sathya Gunasekar (Meta), ML Serving team, Storage & Caching team