

Python 3.13 will be published on October 1, 2024. This new version is a major step forward for the language, although several of the biggest changes are happening under the hood and won’t be immediately visible to you.
In a sense, Python 3.13 is laying the groundwork for some future improvements, especially to the language’s performance. As you read on, you’ll learn more about the background for this and dive into some new features that are fully available now.
In this tutorial, you’ll learn about some of the improvements in the new version, including:
- Improvements made to the interactive interpreter (REPL)
- Clearer error messages that can help you fix common mistakes
- Advancements done in removing the global interpreter lock (GIL) and making Python free-threaded
- The implementation of an experimental Just-In-Time (JIT) compiler
- A host of minor upgrades to Python’s static type system
If you want to try any of the examples in this tutorial, then you’ll need to use Python 3.13. The tutorials Python 3 Installation & Setup Guide and How Can You Install a Pre-Release Version of Python? walk you through several options for adding a new version of Python to your system.
In addition to learning more about the new features coming to the language, you’ll also get some advice about what to consider before upgrading to the new version. Click the link below to download code examples demonstrating the new capabilities of Python 3.13:
Take the Quiz: Test your knowledge with our interactive “Python 3.13: Cool New Features for You to Try” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Python 3.13: Cool New Features for You to Try
In this quiz, you’ll test your understanding of the new features introduced in Python 3.13. By working through this quiz, you’ll review the key updates and improvements in this version of Python.
An Improved Interactive Interpreter (REPL)
If you run Python without specifying any script or code, you’ll find yourself inside Python’s interactive interpreter. This interpreter is informally called the REPL because it’s based on a read-evaluate-print loop. The REPL reads your input, evaluates it, and prints the result before looping back and doing the same thing again.
The Python REPL has been around for decades, and it supports an explorative workflow that makes Python a beginner-friendly language. Unfortunately, the interpreter has been missing several features you may have come to expect, including multiline editing and efficient pasting of code.
Note: Experienced Python developers often install a third-party interactive interpreter instead of relying on the built-in REPL. You can learn more about the alternatives in these tutorials:
You can also read more about alternative REPLs in the guide to the standard REPL.
Begin by starting the REPL. You can do this by typing python in your terminal. Depending on your setup, you may have to write py, python3, or even python3.13 instead. One way to recognize that you’re using the new interpreter shipping with Python 3.13 is that the prompt consisting of three chevrons (>>>) is subtly colored:
One improvement is that you can now use REPL-specific commands without calling them with parentheses as if they are Python functions. Here are some of the commands and keyboard shortcuts you can use:
exitorquit: Exit the interpreterclear: Clear the screenhelpor F1: Access the help system- F2: Open the history browser
- F3: Enter paste mode
You can learn more about these options in Python 3.13 Preview: A Modern REPL.
Recalling code you’ve written earlier has been cumbersome in the REPL before Python 3.13, especially if you’re working with a block of code spanning several lines. Traditionally, you’ve had to bring back each line one by one by repeatedly pressing Up. Now in 3.13, you can bring back the whole block of code with a single Up keystroke.
To try this for yourself, enter the following code in your REPL:
You’re creating a somewhat complex list comprehension that calculates an offset cube of a range of numbers, but only if the numbers are odd. The important part is that for readability, you split the list comprehension over several lines. Now try hitting that Up key! The interpreter recalls all four lines at once, and you can continue to use your arrow keys to move around inside of the expression.
You can make changes to your code and run it again. To execute the updated code, you need to move your cursor to the end of the last line in the code block. If you press Enter inside the expression, you’ll create a new empty line instead:
The ability to recall and edit multiline statements is a huge time-saver and will make you more efficient when working with the REPL.
Another convenience coming in Python 3.13 is proper support for pasting code. In Python 3.12 and earlier, you’d need to make sure that your code doesn’t contain any blank lines before you could copy and paste it. In the new version, pasted code is treated as a unit and executes just as it would inside a script.
This makes it more convenient to use the REPL to interactively tweak and debug your scripts. As an example, say that you want to write a script that can print random numbers, maybe to act as dice in a tabletop game you’re playing:
If you try to copy and paste this code into an older REPL, then it won’t work. The blank line inside the while loop causes issues. You enter an infinite loop that seemingly doesn’t do anything. To stop the loop, you can type q and hit Enter or press Ctrl+C.
In Python 3.13, pasting works without a hitch:
Note that the prompt displays as three dots (...) for all the code that you paste, indicating that it’s all part of one code unit. In this example, you choose to roll a d13, a thirteen-sided die, three times.
Another arena where your Python developer experience gets a small boost in Python 3.13 is through improved error messages, which you’ll learn about next.
Better Error Messages
The REPL is great to work with when you first start using Python, and another feature you quickly run into is Python’s error messages. It hasn’t always felt like the error messages were trying to help you. However, over the last several releases, they’ve gotten friendlier and more helpful:
Python 3.13 continues this great tradition of enhancing your developer experience. In this release, color is added to the tracebacks shown when you encounter a runtime error. Additionally, more kinds of error messages provide you with suggestions on how to fix errors. You’ll look closer at these in this section.
First, you’ll provoke Python and create a runtime error to get a glimpse of the colored tracebacks. Open your REPL and define inverse() as follows:
The inverse() function calculates the multiplicative inverse of a number. One issue that inverse() doesn’t account for, is that zero doesn’t have an inverse. In your function, you see this because inverse(0) raises a ZeroDivisionError:
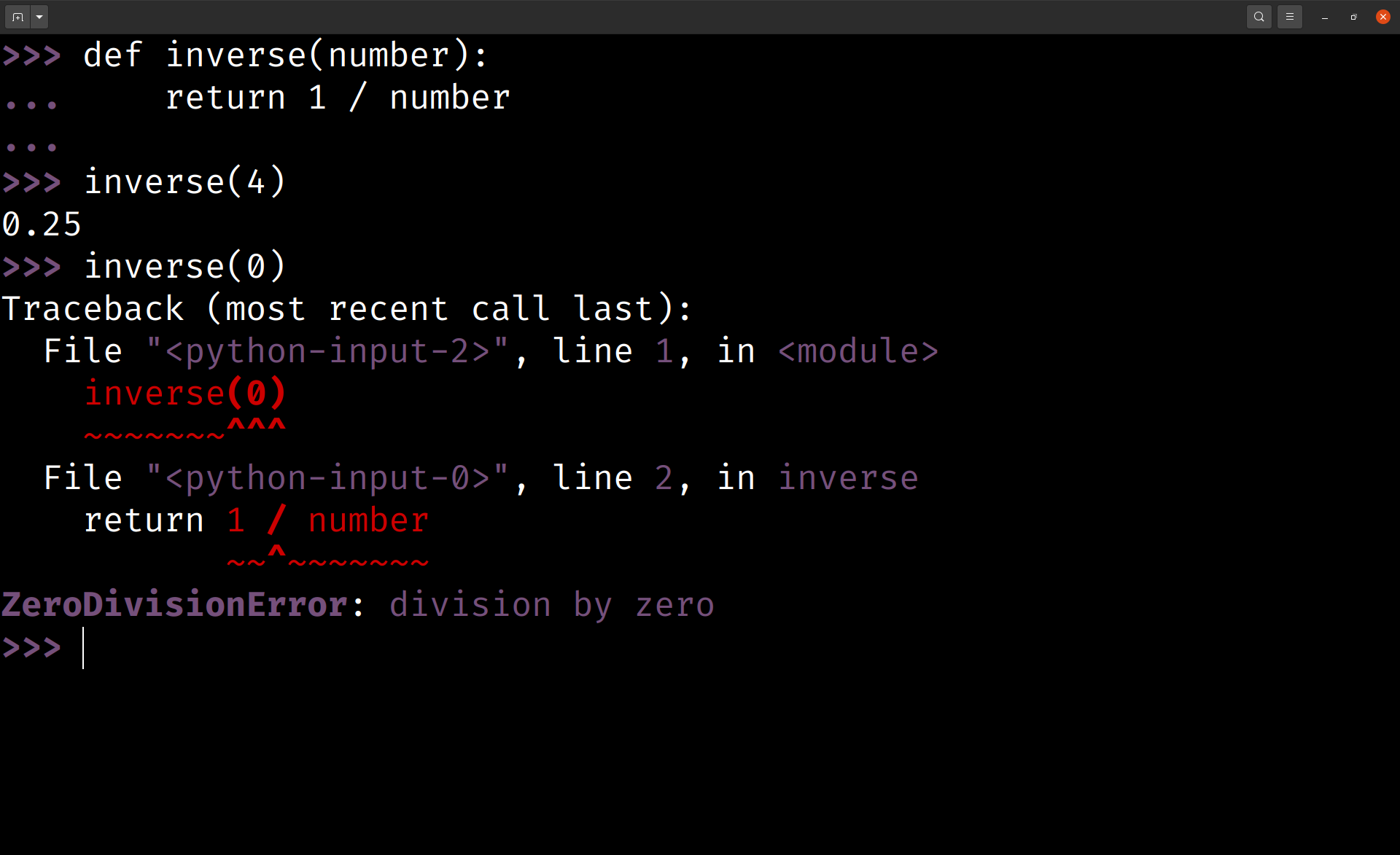
Your tracebacks now have colors, with important information highlighted in red and purple. In general, this should make error messages easier to read and understand.
However, if you don’t like the colors, you can turn them off by setting the PYTHON_COLORS environment variable to 0.
Since Python 3.10, error messages have included a Did you mean suggestion feature that can help you out if you misspell a keyword, function name, or even a module name. In Python 3.13, the suggestions are expanded to include keyword arguments in function calls. Say that you’re trying to sort a list of numbers in descending order:
You try to use reverse=True to sort the numbers in reverse order. At first, you make a typo and call the argument reversed with a d at the end. Python notices this and helpfully suggests that you meant reverse.
Some of the advanced features in Python are backed by simple mechanisms. For example, to create your own Python module, you only need to create a file named with a .py suffix. This is great for exploring the language, but also opens the door for things to go wrong in interesting ways.
The following scenario is something you’ve probably run into. Recall the dice-rolling script from earlier. Say that you had called the file random.py instead:
Your game is waiting on the table and you’re excited to start rolling the dice. Run the script and let randomness unfold:
Error messages like module ‘random’ has no attribute ‘randint’ has confused Python developers for decades. Surely, randint() is one of the functions in the random module!
In Python 3.13, you no longer need to scratch your head, as the error message points out what’s likely the problem. When you created random.py, you created a new random module that shadows the one in the standard library. To fix the problem, you should rename your script.
Note: You can use another workaround to make the example work. If you add the -P option and run python -P random.py, then Python won’t include your current directory in the paths that Python searches during imports, and your script won’t hide the random standard-library module.
Rename random.py back to roll_dice.py and run it again:
Your script is no longer hiding random from the standard library. In the example above, you first roll a regular six-sided die three times, before switching to a twenty-sided die.
You’ll see a similar error message if you happen to shadow a third-party package as well. In general, you should be careful with naming your top-level Python files the same as libraries that you plan to import.
Note: Naming clashes are less of an issue in submodules that are part of a package. For example, you can create a package for serializing data that can serialize to different formats like CSV and JSON.
Inside the package, you can keep format-specific code in files named csv.py and json.py without worrying that these will shadow csv and json in the standard library. This is because these files are not top-level. Instead, you access them with import serialize_package.csv or from serialyze_package import csv.
The continued work on improving your developer experience helps Python defend its position as a beginner-friendly language.
Free-Threaded Python: Look Ma, No GIL
High-level languages like Python provide some conveniences for you as a developer. For example, you can trust that Python will handle memory for you. You don’t need to worry about allocating memory before initializing a data structure, and you don’t need to remember to free the memory when you’re done working with it.
Another programming problem that Python helps you with is making sure that your code is thread-safe. Simply put, for code to be thread-safe, it needs to ensure that two different threads of execution don’t update the same part of memory at the same time.
Python’s solution to this is a bit heavy-handed. It uses a global interpreter lock (GIL) to ensure that only one thread accesses the memory at a time. For most operations, a thread must first acquire the GIL. Because this lock is global—there’s only one GIL—most Python programs are effectively single-threaded, even when they’re running on modern hardware with several CPUs available.
Note: Many libraries that are written in C, including NumPy, are able to bypass the GIL by handling thread safety on their own. Such code can often take advantage of computers with multiple cores.
Historically, the GIL proved to be a simple and effective solution to adding bindings to C libraries that weren’t thread-safe. The GIL has likely played a significant role in Python’s rise in popularity as a programming language.
As the number of CPUs available in computers has increased over the years, the GIL has become more of a troublemaker than a hero. The community has attempted to remove the GIL from the language several times. The most recent attempt, initialized by Sam Gross, is by far the most promising. In fact, you can set up a special free-threaded version of Python 3.13 that doesn’t have a global interpreter lock.
Trying out the free-threaded version of Python requires some time and effort. You may be able to get a version from your platform’s regular distribution channel. If not, you can either download Python’s source code and build it yourself, or run Python through Docker. For more information, see Get Your Hands on the New Features in the free threading preview.
The free-threaded Python executable is typically named python3.13t with a t suffix. Once you have your hands on a free-threaded version of Python, you can choose to enable or disable the GIL each time you run Python:
You enable the GIL and turn off free threading by setting -X gil=1. The pyfeatures module needed to run the above code is available in the downloadable materials. It contains functionality for detecting the status of free threading.
Note that enabling the GIL on the free-threaded version isn’t completely equivalent to running the standard version of Python. At least in early versions of Python 3.13, running the free-threaded version with the GIL enabled shows some issues with performance:
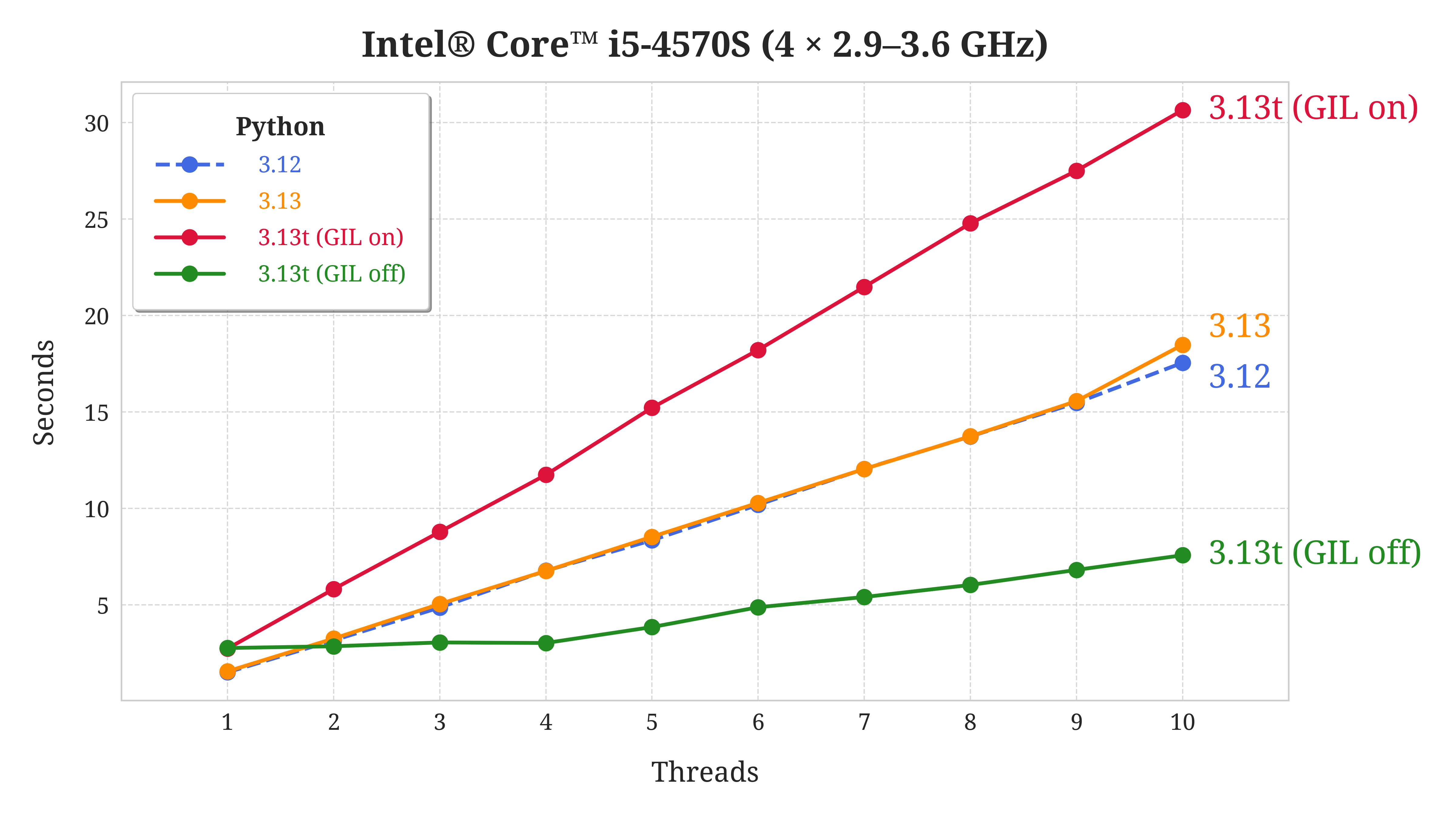
This particular benchmark is run on a computer with four CPUs. Note that the graph for free-threaded Python with the GIL disabled is close to flat for the first four threads. This is very promising, as it indicates that this version of Python is able to take advantage of all cores on the computer.
If you’re interested in learning more about this benchmark, then go ahead and read Measure the Performance Improvements of Python 3.13 which goes more in-depth on the performance of free-threaded Python.
Removing the GIL is a massive undertaking that will hopefully make Python more performant in the future. In the next section, you’ll look at another feature aimed at speeding up Python.
Experimental JIT Compiler
Python is an interpreted language. This is in contrast to languages like C and Rust, which are all compiled languages. In an interpreted language, you need a runtime like a Python interpreter to run your code. Compiled code, on the other hand, can typically be run directly on your system.
There are advantages and disadvantages to both models. Python is often a language that’s efficient for developers, where new code can be tested quickly. But, the code itself may run slower than equivalent compiled code.
A just-in-time, or JIT, compiler provides a kind of middle ground, where the interpreter may choose to compile some code while a program is running in order to speed it up. In Python 3.13, there’s a new, experimental JIT compiler. The fact that it’s experimental means that it’s present in Python’s source code, but it’s not enabled by default.
If you want to try out the JIT compiler, you need to set up a special version of Python 3.13 with the JIT enabled. This is similar to what you need to do to try out free-threaded Python, although with different build flags.
Python’s JIT compiler is based on an algorithm called copy-and-patch. The interpreter will look for patterns in your code that match pre-compiled templates and fill in the machine code with specific information like memory addresses of variables.
JIT compilation can be effective and give better performance in code where the same operation is repeated over and over again, giving the JIT compiler time to analyze and translate your code. In one benchmark, which repeatedly calculated the Fibonacci series, you can see a small improvement in performance with the JIT:
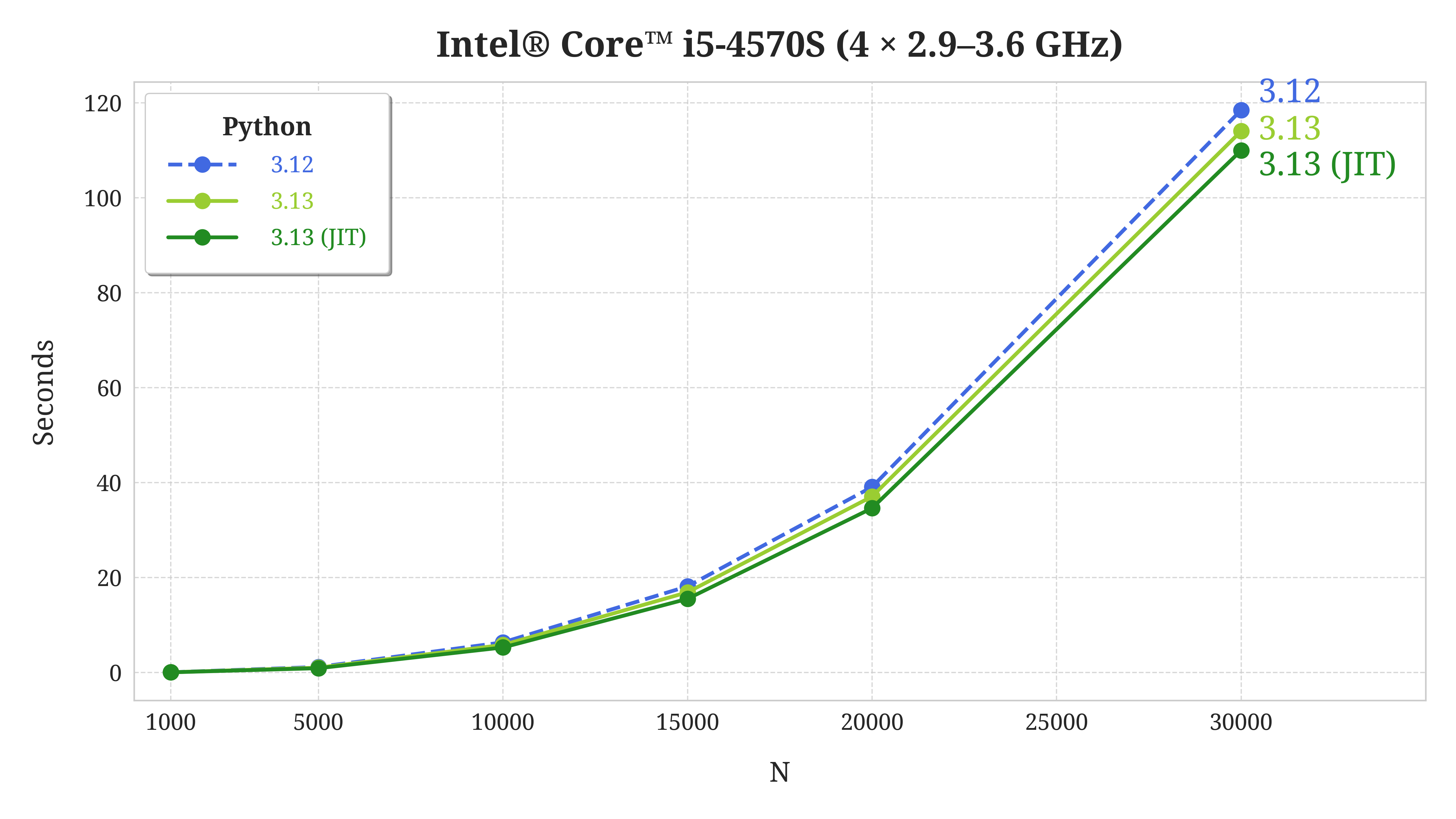
In this benchmark, Python 3.13 with the JIT enabled is faster than both Python 3.12 and regular Python 3.13. However, the JIT isn’t ready for everyday use yet, and you should limit yourself to experimenting with it. Hopefully, the JIT will have more impact in future Python releases.
To learn more about the above benchmark, as well as the new experimental JIT compiler, dig into Python 3.13 Preview: Free Threading and a JIT Compiler.
Improvements to Static Typing
While Python is a dynamically typed language, you can add static type information in optional type hints. You can run a separate type checker like mypy or Pyright to validate your code, or you can rely on your IDE to advise you about issues.
The foundations of Python’s static type system were defined in PEP 484 and introduced in Python 3.5. In November 2023, PEP 729 established the Typing Council and formalized the type system through a typing specification.
The Typing Council governs the Python type system and aims to make it useful, usable, and stable. It maintains the typing specification and advises Python’s Steering Council on typing-related PEPs. The initial members of the Typing Council are:
In addition to providing more clarity in the governance of Python’s type system, the community has implemented some code-related changes as well. The following PEPs have been accepted for Python 3.13:
- PEP 696: Type defaults for type parameters
- PEP 742: Narrowing types with
TypeIs - PEP 705:
TypedDict: Read-only items - PEP 702: Marking deprecations using the type system
In this tutorial, you’ll focus on the first two changes: type defaults and improved type narrowing. If you’re interested in learning more about read-only TypedDict items or deprecations, have a look at their respective PEPs or check out the downloadable materials. The latter contains examples that you can play with on your own.
Similar to other features in the language, typing improvements are tied to a specific version of Python. However, they also require that the type checker you’re using implements the new feature. When possible, new features are backported to older Python versions through the typing_extensions library. For example, you can use TypeIs on, say, Python 3.10 by importing from typing_extensions instead of typing.
Note: In this section, you’ll use Pyright as your type checker. You can install Pyright into your virtual environment using pip:
If you’re using Visual Studio Code, then you can use Pyright inside the editor through the Pylance extension. You may need to activate it by setting the Python › Analysis: Type Checking Mode option in your settings.
Python 3.12 introduced a new syntax for type generics. A generic type is one that’s parametrized by another type. For example, a list is a generic type as you can have a list of strings or a list of integers. Both are lists, but they are parametrized by different types, namely strings and integers.
Traditionally, you’ve needed to explicitly define type variables using TypeVar. Since Python 3.12, you can declare type variables in a more compact [T] syntax using square brackets:
In this example, you create a generic queue based on deque. You can use the queue as follows:
You declare that string_queue will be a queue with string elements by adding [str] in square brackets when you create the instance. Similarly, [int] specifies that integer_queue will have integer elements. If you leave out the square brackets and call Queue() directly, then your queue can have elements of arbitrary type.
You can now specify a type default for these kinds of generic classes. This default will be assumed when you don’t explicitly define a type:
You define the type default similarly to how you specify default arguments for functions. The syntax [T=str] means that if the type of T isn’t specified, then it’ll be str. To confirm this, you use the special reveal_type(). This function is understood by your type checker, but will fail if you run your code:
When you run Pyright on your code, reveal_type() confirms that string_queue is a queue of strings, even if you haven’t explicitly specified it.
Note: You can also use type defaults with the traditional TypeVar syntax, by writing T = TypeVar("T", default=str). See the typing specification for more information.
Type defaults is a small addition that can make working with generics more convenient.
Python 3.10 introduced type guards. These allow you to narrow union types. Consider the following example of a recursively defined tree structure:
Here, is_tree() acts as a type guard that can identify trees. In your code, a Tree is a nested list of integers. The recursive get_left_leaf_value() function takes either a Tree or a single integer. However, after checking is_tree(), you can safely access the first element of the tree on line 12.
Type guards have some limitations where they don’t work well with generic types and they only provide positive guarantees. The latter means that the type checker isn’t allowed to do any type narrowing if the type guard returns False.
In the example above, this means that for a type checker, tree_or_leaf on line 14 is still of type Tree | int:
Here, your type checker complains about the type in your second return statement. However, since this is in the else branch, you know that tree_or_leaf is an int. To convince your type checker of this, you’d need another type guard for integers.
TypeIs is similar to TypeGuard but it provides more type narrowing information to the type checker, and solves the issue with the example above. In many cases, you can use TypeIs as a drop-in replacement for TypeGuard:
You’ve replaced TypeGuard with TypeIs. This provides more information to the type checker. In particular, it knows that tree_or_leaf can’t be a Tree if you enter the else branch on line 13, so tree_or_leaf must be an integer in this case. You can confirm this by running Pyright:
You can read more about type narrowing and the difference between TypeGuard and TypeIs in the typing specification.
While Python’s type system is constantly evolving, most of the new features are actually incremental improvements on existing capabilities. This reflects that static typing in Python is fairly mature at this point.
Other Pretty Cool Features
You’ve seen the highlights of what’s coming in Python 3.13. However, each new release of Python contains tons of little changes contributed by enthusiastic developers. In this section, you’ll check out some of the improvements that don’t necessarily get the big headlines.
A Random Command Line
Python comes with several tools baked in. A couple of the more famous ones are json.tool and http.server. You access these through Python’s -m switch:
You can use json.tool to format JSON files and make them more convenient to read. With http.server, you can quickly run a local HTTP server.
Python 3.13 adds a command-line interface to the random module:
You can quickly create a random number or make a random choice by calling python -m random. Depending on your input you’ll get one of three results back:
- If you pass a list of elements, you’ll get one random element from the list.
- If you pass an integer N, you’ll get a random integer between 1 and N.
- If you pass a float x, you’ll get a random float between 0 and x.
Try it out for yourself:
Whether you want to plan your next random getaway, simulate some dice rolls, or just need a random number, you can now turn to the random module for some quick help. By default, the kind of random result you get depends on what you pass in. However, you can also use options like --choice, --integer, and --float to be explicit:
Here, you get a random floating-point number even if you pass in an integer as a limit because you specified --float. This command-line interface isn’t advanced, but it can be a quick help if you need something random.
New copy.replace() for Modifying Immutable Objects
There are several advantages to working with immutable objects. Since an immutable object can’t change after you’ve created it, it’s straightforward to reason about its state. You can also readily cache immutable objects or use them in distributed contexts.
Python comes with several immutable data structures, including tuples, frozen sets, and frozen data classes. If you represent your data with immutable data structures, then you can still change the state of your data by creating new immutable objects that may share one or more fields with the original.
Consider the following example, modeling a person and their current Python version:
Now, say that your person upgrades to the latest Python version. If Person had been mutable, you could write person.version = "3.13". However, that’s not possible with a named tuple. Instead, you create a new Person object and point person to that new object:
You create a new Person object with the same name and location as before, but update the Python version. This works but can become hard to read, write, and maintain if your data structure has many fields.
Some built-in immutable classes have support for this use case with a dedicated method. For example, you can copy date and datetime objects, replacing one or more fields as you do so:
You use .replace() to calculate the first of the current month, or Christmas Eve this year.
In Python 3.13, a new replace() function is added to the copy module to consistently provide the same functionality to many immutable data structures. You can use copy.replace() to re-create the examples above:
If you don’t provide a new value to a field with replace(), then its original value is kept. When you upgrade the Python version, you only need to specify version and not the other fields. As before, the original object doesn’t change:
You’d need to explicitly update person if that’s what you want.
You can use replace() to modify data classes in addition to named tuples. You can also add a .__replace__() special method if you want replace() to work with your custom class. You’ll find an example of how this works in the downloadable materials.
Improved Globbing of Files and Directories
Python’s pathlib module has many tools for working with paths and files consistently across operating systems. For example, you can list files and directories using .glob():
In this example, you explore the music/ directory on your computer. It contains two items, opera and rap.
Note: The music/ directory has the following structure:
music/
│
├── opera/
│ ├── flower_duet.txt
│ ├── habanera.txt
│ └── nabucco.txt
│
└── rap/
├── bedlam_13-13.txt
└── fight_the_power.txt
You can find the music/ directory in the downloadable materials if you want to follow along yourself.
The .glob() method uses special glob patterns which have been used to represent sets of filenames since the 1970s. You use special wildcard characters like * and ? where * matches any number of any characters, while ? matches any single character.
For example, *.py matches any filename that ends with .py. Similarly, python3.1? matches names like python3.12, python3.13, and python3.1X, but not python3.1 or python3.100.
One special pattern is the globstar (**) which is available in many terminal shells. It matches all files and directories recursively. You can explore music/ in Bash with ls:
Using ls music/**, you list all directories and files inside music/. While Python has supported **, its behavior has been inconsistent with other tools. In Python 3.12, you can observe the following:
Using the globstar only lists directories. If you want to list both directories and files, you need to use the extended **/* pattern.
In Python 3.13, the behavior of ** is changed to be consistent with traditional tools:
Using ** as your glob pattern now lists both directories and files. If you need to constrain your pattern to only show directories, then you can be explicit and add a slash (/) at the end of your pattern:
You add a slash (/) at the end of your pattern to make .glob() only return directories.
Typically, you’ll use .glob() through pathlib. But the functionality is also available in the glob module. Python 3.13 adds a new function, glob.translate() that you can use to convert a glob pattern to a regular expression (regex).
Regular expressions are patterns that you can use to search and match general strings. They are more general and more powerful than glob patterns, but they’re also more complex. If you need more flexibility when working with a glob pattern, you can try to translate it into a regular expression:
You translate the glob pattern that matches any .txt file nested inside music/ into a regular expression. You can then match the regex pattern against any string using re.match():
In this example, your two file paths match the pattern, while the directory path doesn’t.
Pathlib now uses glob.translate() internally for several operations. This comes with a small performance boost as directories can be walked faster and Path objects can be smaller.
Naked Docstrings
Python stores inline documentation in docstrings. You can access these through the help system. At runtime, you can also access docstrings through .__doc__:
You’ve added a docstring to Person by writing a text string immediately after the class statement. It’s a convention to use triple-quoted strings for docstrings. You can access the docstring by looking at the .__doc__ special attribute.
Because docstrings are typically written inside a function, method, or class definition, they’ll contain a fair bit of spaces. The indentation Python requires is reflected in the docstring. On Python 3.12, you’ll see something like this:
Note that every line in the docstring, except the first one, contains between four and ten leading spaces. In Python 3.13, docstrings are stripped! They’re stored with the common leading whitespace removed. Rerun the same example in the newest Python version:
In this case, four spaces have been removed from every line except the first one. This is a small optimization that means that docstrings take up less memory than before.
If you have code that relies on the exact value of .__doc__, you should test it to make sure it still behaves as expected in Python 3.13.
So, Should You Upgrade to Python 3.13?
You’ve seen several of the features coming in Python 3.13. There are even many more that you can read about in the Python changelog. Improved features not covered in this tutorial include:
Additionally, Python’s annual release cycle has been revised to extend full support from eighteen months to a full two years. Each release will still get security fixes for five years:
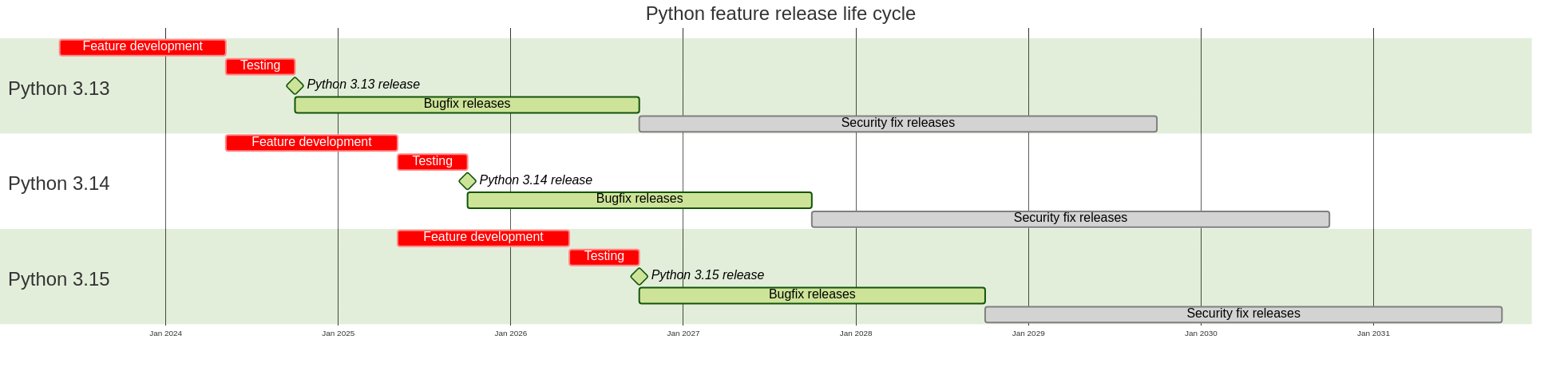
The diagram shows the life cycles of Python 3.13 and the upcoming 3.14 and 3.15.
So, having seen all these new improvements, should you upgrade to Python 3.13? Like for every release, the answer is a clear and loud it depends!
There isn’t any big reason not to update your local environment that you use for exploring the language. The new REPL and improved error messages are nice quality-of-life upgrades and you might see some small performance improvements. That said, if you don’t use the built-in REPL, there aren’t any super attractive features that you need to jump on either.
If you’re maintaining a library, especially one that uses Python’s C-API, you should start testing with Python 3.13, both the regular version and the free-threaded one. It’s important to surface any bugs in the implementation as soon as possible. Adding a bug report is a great contribution to the language. Your library may also need some updates to be compatible with free threading.
For code that’s running in production, you should be as diligent as ever with testing your code on Python 3.13 before upgrading your runtime. While a lot of testing has been done since Python 3.13 reached beta in May 2024, there are always bugs that surface after the official release. For critical code, you’ll be fine with running on Python 3.12 until its full support ends in April 2025.
A question that’s independent of when you upgrade your Python is when you should start using the new features. Again, it depends on your code and your situation.
This time around, there aren’t any big syntax changes, like f-strings, the walrus operator, or the match…case statement in the past. Instead, there are some functions, like copy.replace() and glob.translate() that will only be available for you on Python 3.13.
If you work on an application where you can control the running environment, you can use Python 3.13 features as soon as you’ve upgraded the environment. If you work on a team, then you need to make sure everyone’s on board and upgraded before you introduce any incompatible syntax.
If you write a library that others use, then you don’t know which version of Python they’ll be using. In this case, it pays off to be more conservative and ideally support each version throughout its lifetime. Python 3.8 reaches end-of-support in October 2024, so you could start looking at requiring Python 3.9 as your minimal version.
Moving forward, there will be bugfix releases of Python 3.13. These are planned to be released approximately every two months. If you start using Python 3.13, you should stay up-to-date with the bugfix updates, and upgrade your environment as they become available.
Conclusion
A new Python release is always great news! You’ve been on a tour of the features and improvements that have been updated in Python 3.13. Send some appreciation to all the volunteers that put time and effort into the development!
In this tutorial, you’ve seen new features and improvements, like:
- Improvements made to the interactive interpreter (REPL)
- Clearer error messages that can help you fix common mistakes
- Advancements done in removing the global interpreter lock (GIL) and making Python free-threaded
- The implementation of an experimental Just-In-Time (JIT) compiler
- A host of minor upgrades to Python’s static type system
You probably won’t be able to take advantage of the new features right away, but you should install Python 3.13 on your system and play with it.
Take the Quiz: Test your knowledge with our interactive “Python 3.13: Cool New Features for You to Try” quiz. You’ll receive a score upon completion to help you track your learning progress:

Interactive Quiz
Python 3.13: Cool New Features for You to Try
In this quiz, you’ll test your understanding of the new features introduced in Python 3.13. By working through this quiz, you’ll review the key updates and improvements in this version of Python.


