Researchers at Stanford Present ZIP-FIT : A Novel Data Selection AI Framework that Chooses Compression Over Embeddings to Finetune Models on Domain Specific Tasks
Data Selection for domain-specific art is an intricate craft, especially if we want to get the desired results from Language Models. Until now, researchers have focused on creating diverse datasets across tasks, which has proved helpful for general-purpose training. However in domain and task-specific fine-tuning where data is relevant, current methods prove ineffective where they either ignore task-specific requirements entirely or rely on approximations that fail to capture the nuanced patterns needed for complex tasks. In this article, we see how the latest research catches up to this problem and makes pre-training data domain-driven.
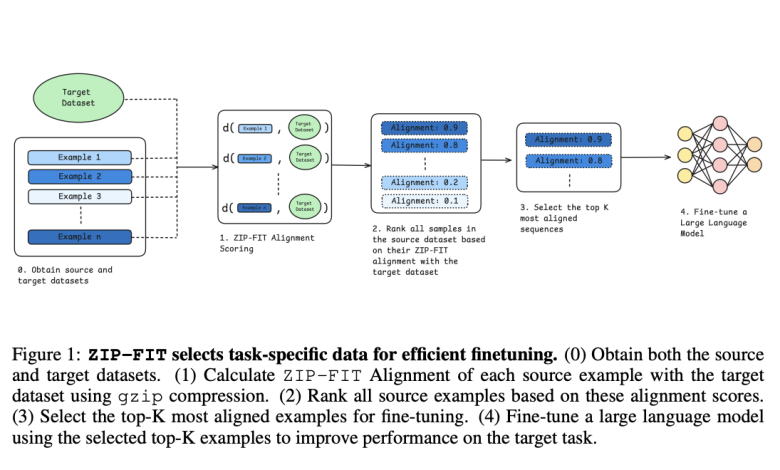
Researchers at Stanford University proposed ZIP- FIT,a novel data selection framework that uses gzip compression to directly measure alignment between potential training data and the target task distributions. ZIP-FIT utilizes compression algorithms to align training data with desired target data which eliminates embeddings and makes the whole process computationally light-weight. Furthermore the synonymy of compression with neural network embeddings in terms of performance ensures that the data meets benchmark quality. Before ZIP-FIT researches that focussed on task-specific data curation often relied upon simplistic and noisy representations which resulted in collisions and noise. For instance one of the methods utilized neural embeddings to measure similarity between data points and reference corpus. Another method used hashed n-gram distributions of the target data for selecting data points. These were ineffective in complex and correlated tasks.
ZIP-FIT addressed the above challenges by capturing both syntactic and structural data patterns pertinent to target tasks with gzip compression-based similarity.gzip compression consists of two compression methods – a) LZ77 b) Huffman coding. Said methods work in unison to exploit repeated patterns in data and on its basis compress the sequence.The compression has the objective to focus on the most relevant data bits and maximize the efficacy of model training.
Zip-Fit was evaluated on two domain focussed tasks namely, Autoformalization and Python Code Generation.
Before delving further, it would be wise to understand what autoformalization is and why it was chosen as an evaluation metric. It is the task of translating natural language mathematical statements into formal mathematical programming languages. Autoformalization requires domain expertise and a very clear understanding of mathematics and programming syntaxes which makes it suitable for testing the domain performance of LLMs. When ZIP-FIT was used to fine-tune datasets on LLMs such as GPT 2 and Mistral, authors found that losses decreased quickly and significantly with increasing alignment with task data. Models trained on ZIP-FIT-selected data achieve their low- est cross-entropy loss up to 85.1% faster than baselines.
For the task of autoformalization, it outperformed other alignment methods by achieving up to 65.8% faster convergence over DSIR, another data selection method. The processing time was also reduced by up to 25%. Similarly, in code generation tasks ZIP FIT data fine-tuned CodeGemma2 and Gemma2 performed significantly better. One major insight that the research team presented in the research was the supremacy of smaller but well-domain-aligned datasets performed better than extensive but less aligned datasets.
ZIP-FIT showed that targeted data selection can dramatically improve task-specific performance over a generalized training approach. ZIP-FIT presents an efficient and cost-effective domain-specialized training approach. However, this method had some shortcomings such as the inability of compression to capture nuanced semantic relationships between dense representations and high dependence on textual data. It would be interesting to see if ZIP-FIT initiates more robust research in domain finetuning and if its shortcomings could be overcome to include more chaotic and unstructured data.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
Adeeba Alam Ansari is currently pursuing her Dual Degree at the Indian Institute of Technology (IIT) Kharagpur, earning a B.Tech in Industrial Engineering and an M.Tech in Financial Engineering. With a keen interest in machine learning and artificial intelligence, she is an avid reader and an inquisitive individual. Adeeba firmly believes in the power of technology to empower society and promote welfare through innovative solutions driven by empathy and a deep understanding of real-world challenges.