
Differentiable Adaptive Merging (DAM): A Novel AI Approach to Model Integration
Model merging, particularly within the realm of large language models (LLMs), presents an intriguing challenge that addresses the growing demand for versatile AI systems. These models often possess specialized capabilities such as multilingual proficiency or domain-specific expertise, making their integration crucial for creating more robust, multi-functional systems. However, merging LLMs effectively is not trivial; it often requires deep expertise and significant computational resources to balance different training methods and fine-tuning processes without deteriorating overall performance. To simplify this process and reduce the complexity associated with current model merging techniques, researchers are striving to develop more adaptive, less resource-intensive merging methods.
Researchers from Arcee AI and Liquid AI propose a novel merging technique called Differentiable Adaptive Merging (DAM). DAM aims to tackle the complexities of merging language models by offering an efficient, adaptive method that reduces the computational overhead typically associated with current model merging practices. Specifically, DAM provides an alternative to compute-heavy approaches like evolutionary merging by optimizing model integration through scaling coefficients, enabling simpler yet effective merging of multiple LLMs. The researchers also conducted a comparative analysis of DAM against other merging approaches, such as DARE-TIES, TIES-Merging, and simpler methods like Model Soups, to highlight its strengths and limitations.
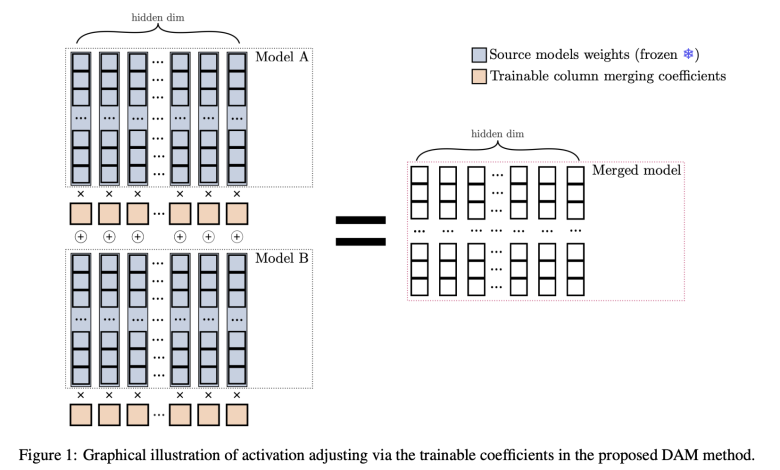
The core of DAM is its ability to merge multiple LLMs using a data-informed approach, which involves learning optimal scaling coefficients for each model’s weight matrix. The method is applicable to various components of the models, including linear layers, embedding layers, and layer normalization layers. DAM works by scaling each column of the weight matrices to balance the input features from each model, thus ensuring that the merged model retains the strengths of each contributing model. The objective function of DAM combines several components: minimizing Kullback-Leibler (KL) divergence between the merged model and the individual models, cosine similarity loss to encourage diversity in scaling coefficients, and L1 and L2 regularization to ensure sparsity and stability during training. These elements work in tandem to create a robust and well-integrated merged model capable of handling diverse tasks effectively.
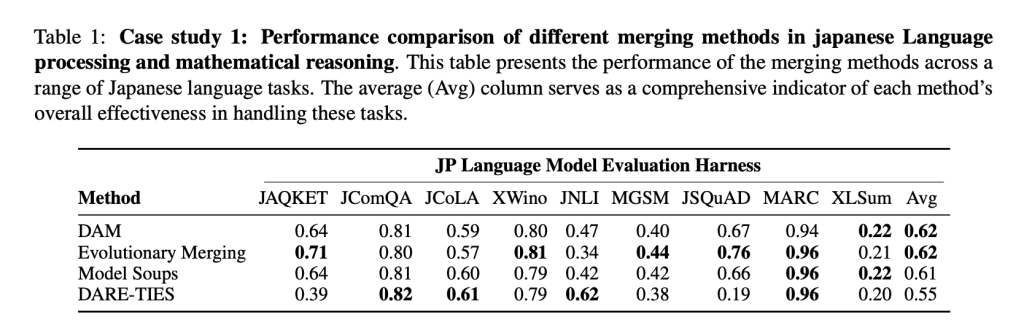
The researchers performed extensive experiments to compare DAM with other model merging methods. The evaluation was conducted across different model families, such as Mistral and Llama 3, and involved merging models with diverse capabilities, including multilingual processing, coding proficiency, and mathematical reasoning. The results showed that DAM not only matches but, in some cases, outperforms more computationally demanding techniques like Evolutionary Merging. For example, in a case study focusing on Japanese language processing and mathematical reasoning, DAM demonstrated superior adaptability, effectively balancing the specialized capabilities of different models without the intensive computational requirements of other methods. Performance was measured using multiple metrics, with DAM generally scoring higher or on par with alternatives across tasks involving language comprehension, mathematical reasoning, and structured query processing.
The research concludes that DAM is a practical solution for merging LLMs with reduced computational cost and manual intervention. This study also emphasizes that more complex merging methods, while powerful, do not always outperform simpler alternatives like linear averaging when models share similar characteristics. DAM proves that focusing on efficiency and scalability without sacrificing performance can provide a significant advantage in AI development. Moving forward, researchers intend to explore DAM’s scalability across different domains and languages, potentially expanding its impact on the broader AI landscape.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.




