I wrote my last post on fpdf2 18 months ago.
We released 7 more versions of fpdf2 since then!
This article will present some of the major features introduced since v2.7.3 to v2.8.1 of fpdf2:
click on the buttons below to reveal the various changes brought to the library.
fpdf2 joined the @py-pdf GitHub organization, that also hosts pypdf, PyPDF-Builder, pdfly and pypdf_table_extraction.
The reasons for this move were detailed in discussion #752.
fpdf2 also welcomes two new maintainers: Anderson Herzogenrath da Costa (@andersonhc) and Georg Mischler (@gmischler).
More details about them in discussion #896 & discussion #898.
A new FPDF.set_text_shaping() method has been introduced to perform text shaping using Harfbuzz, thanks to @andersonhc: documentation page on text shaping.

Previously only supported when rendering SVG images,
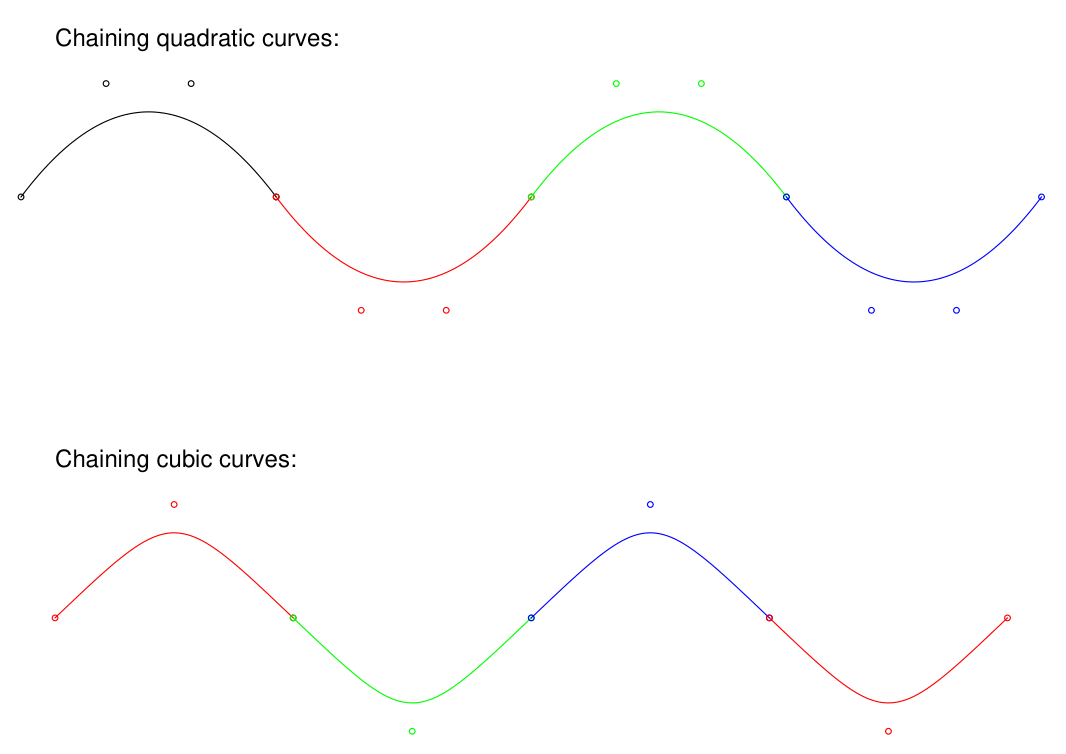
quadratic & cubic Bezier curves can now be directly rendered using the new FPDF.bezier() method, thanks to @awmc000: documentation on Bezier curves.
Support for Free Text annotations was added by @MarekT0v in PR #1039 : documentation on Free Text annotations.

We added more guides detailing how to combine fpdf2 with other libraries:
Several improvements were made regarding tables :
- links, padding & vertical alignment in cells with
v_align - new parameters
gutter_height,gutter_widthandwrapmode - control over outer border width
- allowing for multiple heading rows, and control over headings repetition over pages
- custom
cell_fill_modelogic can now be provided - cells that span multiple rows via the
rowspanattribute, which can be combined withcolspan
Various improvements regarding our basic HTML renderer:
- support for CSS page breaks properties
- support for
start&typeattributes of<ol>tags, andtypeattribute of<ul>tags tag_stylesto control the font, color, size & indent of most HTML elementsli_prefix_colorto control the color of list prefixes (bullets & numbers)
FPDF.write_html()now uses the newFPDF.table()method to render<table>tags.- font aliases are deprecated (
Arial→Helvetica,CourierNew→Courier,TimesNewRoman→Times), they will be removed in a later release. - to improve naming consistency, the
txtparameters ofFPDF.cell(),FPDF.multi_cell(),FPDF.text()&FPDF.write()have been renamed totext. - the
split_onlyoptional parameter ofFPDF.multi_cell()has been replaced by two new distincts optional parameters:dry_run&output. fpdf.TitleStylehas been renamed intofpdf.TextStyle.- we removed an obscure and undocumented feature of
FPDF.write_html(), which used to magically pass local variables as arguments.
In order to do “our part” to contribute to a more secure Python ecosystem,
fpdf2 releases are now performed using Pypi Trusted Publishers : Pypi blog announcement.
New tutorials :
I would also like to celebrate that, as spotted by @gmischler in discussion #1232, fpdf2 has exceeded 1000 stars on GitHub!
Yes, it’s a bit superficial, but I’d like to thank all the programmers who have expressed their support for fpdf2: it makes me happy to know that this project is useful to you 🙂

Because such retrospective time is also an opportunity to reflect on things that did not go well,
I would like to mention a few failures:
-
we’ve had a couple of Pull Requests left unanswered for almost a year… 😞 I will try to be more vigilant about this, as I know not having feedback can really kill developers’ motivation.
-
I spotted a bug while using the excellent
pdflyCLI tool to extract pages from a PDF document built withfpdf2: the resulting file was excessively big. After adding a unit test topdflyto investigate (in PR #45), I realized that this was due to a slightly invalid structure in the PDF documents produced byfpdf2. All the PDF readers I tested did not care, but thepypdflibrary (used bypdfly) was using this information to properly extract pages from a file. This is now all fixed! -
I initially performed a release for
fpdf2version 2.8.0, but then erroneously removed it on Pypi, erroneously fearing a regression 😅 Versions 2.8.0 & 2.8.1 are exactly the same.
Finally, Hacktoberfest is currently running, and we have many issues up-for-grabs at fpdf2, so come help and contribute some code! 🙂