This post is cowritten with Ethan Handel and Zhiyuan He from Indeed.com.
Indeed is the world’s #1 job site¹ and a leading global job matching and hiring marketplace. Our mission is to help people get jobs. At Indeed, we serve over 350 million global Unique Visitors monthly² across more than 60 countries, powering millions of connections to new job opportunities every day. Since our founding nearly two decades ago, machine learning (ML) and artificial intelligence (AI) have been at the heart of building data-driven products that better match job seekers with the right roles and get people hired.
On the Core AI team at Indeed, we embody this legacy of AI innovation by investing heavily in HR domain research and development. We provide teams across the company with production-ready, fine-tuned large language models (LLMs) based on state-of-the-art open source architectures. In this post, we describe how using the capabilities of Amazon SageMaker has accelerated Indeed’s AI research, development velocity, flexibility, and overall value in our pursuit of using Indeed’s unique and vast data to leverage advanced LLMs.
Infrastructure challenges
Indeed’s business is fundamentally text-based. Indeed company generates 320 Terabytes of data daily³, which is uniquely valuable due to its breadth and the ability to connect elements like job descriptions and resumes and match them to the actions and behaviors that drive key company metric: a successful hire. LLMs represent a significant opportunity to improve how job seekers and employers interact in Indeed’s marketplace, with use cases such as match explanations, job description generation, match labeling, resume or job description skill extraction, and career guides, among others.
Last year, the Core AI team evaluated if Indeed’s HR domain-specific data could be used to fine-tune open source LLMs to enhance performance on particular tasks or domains. We chose the fine-tuning approach to best incorporate Indeed’s unique knowledge and vocabulary around mapping the world of jobs. Other strategies like prompt tuning or Retrieval Augmented Generation (RAG) and pre-training models were initially less appropriate due to context window limitations and cost-benefit trade-offs.
The Core AI team’s objective was to explore solutions that addressed the specific needs of Indeed’s environment by providing high performance for fine-tuning, minimal effort for iterative development, and a pathway for future cost-effective production inference. Indeed was looking for a solution that addressed the following challenges:
- How do we efficiently set up repeatable, low-overhead patterns for fine-tuning open-source LLMs?
- How can we provide production LLM inference at Indeed’s scale with favorable latency and costs?
- How do we efficiently onboard early products with different request and inference patterns?
The following sections discuss how we addressed each challenge.
Solution overview
Ultimately, Indeed’s Core AI team converged on the decision to use Amazon SageMaker to solve for the aforementioned challenges and meet the following requirements:
- Accelerate fine-tuning using Amazon SageMaker
- Serve production traffic quickly using Amazon SageMaker inference
- Enable Indeed to serve a variety of production use cases with flexibility using Amazon SageMaker generative AI inference capabilities (inference components)
Accelerate fine-tuning using Amazon SageMaker
One of the primary challenges that we faced was achieving efficient fine-tuning. Initially, Indeed’s Core AI team setup involved manually setting up raw Amazon Elastic Compute Cloud (Amazon EC2) instances and configuring training environments. Scientists had to manage personal development accounts and GPU schedules, leading to development overhead and resource under-utilization. To address these challenges, we used Amazon SageMaker to initiate and manage training jobs efficiently. Transitioning to Amazon SageMaker provided several advantages:
- Resource optimization – Amazon SageMaker offered better instance availability and billed only for the actual training time, reducing costs associated with idle resources
- Ease of setup – We no longer needed to worry about the setup required for running training jobs, simplifying the process significantly
- Scalability – The Amazon SageMaker infrastructure allowed us to scale our training jobs efficiently, accommodating the growing demands of our LLM fine-tuning efforts
Smoothly serve production traffic using Amazon SageMaker inference
To better serve Indeed users with LLMs, we standardized the request and response formats across different models by employing open source software as an abstraction layer. This layer converted the interactions into a standardized OpenAI format, simplifying integration with various services and providing consistency in model interactions.
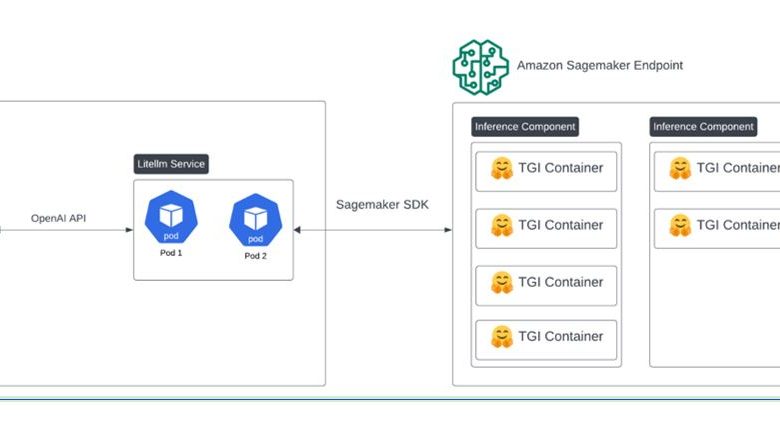
We built an inference infrastructure using Amazon SageMaker inference to host fine-tuned Indeed in-house models. The Amazon SageMaker infrastructure provided a robust service for deploying and managing models at scale. We deployed different specialized models on Amazon SageMaker inference endpoints. Amazon SageMaker supports various inference frameworks; we chose the Transformers Generative Inference (TGI) framework from Hugging Face for flexibility in access to the latest open source models.
The setup on Amazon SageMaker inference has enabled rapid iteration, allowing Indeed to experiment with over 20 different models in a month. Furthermore, the robust infrastructure is capable of hosting dynamic production traffic, handling up to 3 million requests per day.
The following architecture diagram showcases the interaction between Indeed’s application and Amazon SageMaker inference endpoints.
Serve a variety of production use cases with flexibility using Amazon SageMaker generative AI inference components
Results from LLM fine-tuning revealed performance benefits. The final challenge was quickly implementing the capability to serve production traffic to support real, high-volume production use cases. Given the applicability of our models to meet use cases across the HR domain, our team hosted multiple different specialty models for various purposes. Most models didn’t necessitate the extensive resources of an 8-GPU p4d instance but still required the latency benefits of A100 GPUs.
Amazon SageMaker recently introduced a new feature called inference components that significantly enhances the efficiency of deploying multiple ML models to a single endpoint. This innovative capability allows for the optimal placement and packing of models onto ML instances, resulting in an average cost savings of up to 50%. The inference components abstraction enables users to assign specific compute resources, such as CPUs, GPUs, or AWS Neuron accelerators, to each individual model. This granular control allows for more efficient utilization of computing power, because Amazon SageMaker can now dynamically scale each model up or down based on the configured scaling policies. Furthermore, the intelligent scaling offered by this capability automatically adds or removes instances as needed, making sure that capacity is met while minimizing idle compute resources. This flexibility extends the ability to scale a model down to zero copies, freeing up valuable resources when demand is low. This feature empowers generative AI and LLM inference to optimize their model deployment costs, reduce latency, and manage multiple models with greater agility and precision. By decoupling the models from the underlying infrastructure, inference components offer a more efficient and cost-effective way to use the full potential of Amazon SageMaker inference.
Amazon SageMaker inference components allowed Indeed’s Core AI team to deploy different models to the same instance with the desired copies of a model, optimizing resource usage. By consolidating multiple models on a single instance, we created the most cost-effective LLM solution available to Indeed product teams. Furthermore, with inference components now supporting dynamic auto scaling, we could optimize the deployment strategy. This feature automatically adjusts the number of model copies based on demand, providing even greater efficiency and cost savings, even compared to third-party LLM providers.
Since integrating inference components into the inference design, Indeed’s Core AI team has built and validated LLMs that have served over 6.5 million production requests.
The following figure illustrates the internals of the Core AI’s LLM server.

The simplicity of our Amazon SageMaker setup significantly improves setup speed and flexibility. Today, we deploy Amazon SageMaker models using the Hugging Face TGI image in a custom Docker container, giving Indeed instant access to over 18 open source model families.
The following diagram illustrates Indeed’s Core AI flywheel.

Core AI’s business value from Amazon SageMaker
The seamless integration of Amazon SageMaker inference components, coupled with our team’s iterative enhancements, has accelerated our path to value. We can now swiftly deploy and fine-tune our models, while benefiting from robust scalability and cost-efficiency—a significant advantage in our pursuit of delivering cutting-edge HR solutions to our customers.
Maximize performance
High-velocity research enables Indeed to iterate on fine-tuning approaches to maximize performance. We have fine-tuned over 75 models to advance research and production objectives.
We can quickly validate and improve our fine-tuning methodology with many open-source LLMs. For instance, we moved from fine-tuning base foundation models (FMs) with third-party instruction data to fine-tuning instruction-tuned FMs based on empirical performance improvements.
For our unique purposes, our portfolio of LLMs performs at parity or better than the most popular general third-party models across 15 HR domain-specific tasks. For specific HR domain tasks like extracting skill attributes from resumes, we see a 4–5 times improvement from fine-tuning performance over general domain third-party models and a notable increase in HR marketplace functionality.
The following figure illustrates Indeed’s inference continuous integration and delivery (CI/CD) workflow.

The following figure presents some task examples.

High flexibility
Flexibility allows Indeed to be on the frontier of LLM technology. We can deploy and test the latest state-of-the-art open science models on our scalable Amazon SageMaker inference infrastructure immediately upon availability. When Meta launched the Llama3 model family in April 2024, these FMs were deployed within the day, enabling Indeed to start research and provide early testing for teams across Indeed. Within weeks, we fine-tuned our best-performing model to-date and released it. The following figure illustrates an example task.

Production scale
Core AI developed LLMs have already served 6.5 million live production requests with a single p4d instance and a p99 latency of under 7 seconds.
Cost-efficiency
Each LLM request through Amazon SageMaker is on average 67% cheaper than the prevailing third-party vendor model’s on-demand pricing in early 2024, creating the potential for significant cost savings.
Indeed’s contributions to Amazon SageMaker inference: Enhancing generative AI inference capabilities
Building upon the success of their use case, Indeed has been instrumental in partnering with the Amazon SageMaker inference team to provide inputs to help AWS build and enhance key generative AI capabilities within Amazon SageMaker. Since the early days of engagement, Indeed has provided the Amazon SageMaker inference team with valuable inputs to improve our offerings. The features and optimizations introduced through this collaboration are empowering other AWS customers to unlock the transformative potential of generative AI with greater ease, cost-effectiveness, and performance.
“Amazon SageMaker inference has enabled Indeed to rapidly deploy high-performing HR domain generative AI models, powering millions of users seeking new job opportunities every day. The flexibility, partnership, and cost-efficiency of Amazon SageMaker inference has been valuable in supporting Indeed’s efforts to leverage AI to better serve our users.”
– Ethan Handel, Senior Product Manager at Indeed.
Conclusion
Indeed’s implementation of Amazon SageMaker inference components has been instrumental in solidifying the company’s position as an AI leader in the HR industry. Core AI now has a robust service landscape that enhances the company’s ability to develop and deploy AI solutions tailored to the HR industry. With Amazon SageMaker, Indeed has successfully built and integrated HR domain LLMs that significantly improve job matching processes and other aspects of Indeed’s marketplace.
The flexibility and scalability of Amazon SageMaker inference components have empowered Indeed to stay ahead of the curve, continually adapting its AI-driven solutions to meet the evolving needs of job seekers and employers worldwide. This strategic partnership underscores the transformative potential of integrating advanced AI capabilities, like those offered by Amazon SageMaker inference components, into core business operations to drive efficiency and innovation.
¹Comscore, Unique Visitors, June 2024
²Indeed Internal Data, average monthly Unique Visitors October 2023 – March 2024
³Indeed data
About the Authors
 Ethan Handel is a Senior Product Manager at Indeed, based in Austin, TX. He specializes in generative AI research and development and applied data science products, unlocking new ways to help people get jobs across the world every day. He loves solving big problems and innovating with how Indeed gets value from data. Ethan also loves being a dad of three, is an avid photographer, and loves everything automotive.
Ethan Handel is a Senior Product Manager at Indeed, based in Austin, TX. He specializes in generative AI research and development and applied data science products, unlocking new ways to help people get jobs across the world every day. He loves solving big problems and innovating with how Indeed gets value from data. Ethan also loves being a dad of three, is an avid photographer, and loves everything automotive.
 Zhiyuan He is a Staff Software Engineer at Indeed, based in Seattle, WA. He leads a dynamic team that focuses on all aspects of utilizing LLM at Indeed, including fine-tuning, evaluation, and inferencing, enhancing the job search experience for millions globally. Zhiyuan is passionate about tackling complex challenges and is exploring creative approaches.
Zhiyuan He is a Staff Software Engineer at Indeed, based in Seattle, WA. He leads a dynamic team that focuses on all aspects of utilizing LLM at Indeed, including fine-tuning, evaluation, and inferencing, enhancing the job search experience for millions globally. Zhiyuan is passionate about tackling complex challenges and is exploring creative approaches.
 Alak Eswaradass is a Principal Solutions Architect at AWS based in Chicago, IL. She is passionate about helping customers design cloud architectures using AWS services to solve business challenges and is enthusiastic about solving a variety of ML use cases for AWS customers. When she’s not working, Alak enjoys spending time with her daughters and exploring the outdoors with her dogs.
Alak Eswaradass is a Principal Solutions Architect at AWS based in Chicago, IL. She is passionate about helping customers design cloud architectures using AWS services to solve business challenges and is enthusiastic about solving a variety of ML use cases for AWS customers. When she’s not working, Alak enjoys spending time with her daughters and exploring the outdoors with her dogs.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, multi-tenant models, cost optimizations, and making deployment of generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, multi-tenant models, cost optimizations, and making deployment of generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
 Brett Seib is a Senior Solutions Architect, based in Austin, Texas. He is passionate about innovating and using technology to solve business challenges for customers. Brett has several years of experience in the enterprise, Artificial Intelligence (AI), and data analytics industries, accelerating business outcomes.
Brett Seib is a Senior Solutions Architect, based in Austin, Texas. He is passionate about innovating and using technology to solve business challenges for customers. Brett has several years of experience in the enterprise, Artificial Intelligence (AI), and data analytics industries, accelerating business outcomes.