
NVIDIA AI Releases OpenMathInstruct-2: A Math Instruction Tuning Dataset with 14M Problem-Solution Pairs Generated Using the Llama3.1-405B-Instruct Model
Language models have made significant strides in mathematical reasoning, with synthetic data playing a crucial role in their development. However, the field faces significant challenges due to the closed-source nature of the largest math datasets. This lack of transparency raises concerns about data leakage and erodes trust in benchmark results, as evidenced by performance drops when models are tested on unpublished, distributionally similar sets. Also, it hinders practitioners from fully comprehending the impact of data composition and algorithmic choices. While open-source alternatives exist, they often come with restrictive licenses or limitations in question diversity and difficulty levels. These issues collectively impede progress and broader application of mathematical reasoning capabilities in language models.
Several datasets have been developed to enhance the mathematical reasoning abilities of language models. NuminaMath and Skywork-MathQA offer large collections of competition-level problems with chain-of-thought annotations and diverse augmentation techniques. MuggleMath focuses on complicating and diversifying queries, while MetaMathQA employs bootstrapping and advanced reasoning techniques. MAmmoTH2 introduced an efficient method for extracting instruction data from pre-training web corpora. Other approaches have expanded existing datasets like MATH and GSM8K, significantly improving model accuracy.
Tool-integrated methods have gained prominence, with the Program of Thoughts (PoT) approach combining text and programming language statements for problem-solving. Building on this concept, datasets like OpenMathInstruct-1 and InfinityMATH have been created, focusing on code-interpreter solutions and programmatic mathematical reasoning. These diverse approaches aim to address the limitations of earlier datasets by increasing question diversity, difficulty levels, and reasoning complexity.
The proposed approach by the researchers from NVIDIA, built upon previous approaches, utilizing chain-of-thought-based solutions and question augmentation to create a robust dataset. However, it introduces several key innovations that set it apart from existing work. Firstly, the method employs open-weight models instead of proprietary closed-source language models, enabling the release of the dataset under a permissive license. This approach enhances accessibility and transparency in the field. Secondly, it provides new insights into critical aspects of dataset creation, including the impact of low-quality data, the effectiveness of on-policy training, and the design of solution formats. Lastly, the method ensures result accuracy through a comprehensive decontamination process, utilizing an LLM-based pipeline capable of detecting rephrased variations of test set questions, thus addressing concerns about data leakage and benchmark validity.
The OpenMathInstruct-2 utilizes the Llama3.1 family of models to generate synthetic math instruction tuning data. The approach is refined through careful ablation studies on the MATH dataset, revealing several key insights. The proposed chain-of-thought solution format outperforms Llama’s format by 3.9% while being 40% shorter. Data generated by a strong teacher model surpasses on-policy data from a weaker student model by 7.8%. The method demonstrates robustness to up to 20% of low-quality data, and increasing question diversity significantly improves performance.
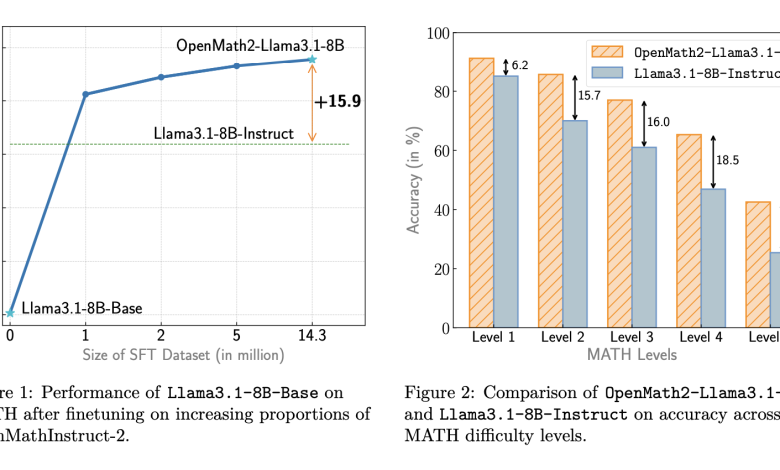
The dataset is created using Llama-3.1-405B-Instruct to synthesize solutions for existing MATH and GSM8K questions and generate new question-solution pairs. A thorough decontamination process, including the lm-sys pipeline and manual inspection, ensures test set integrity. The resulting dataset comprises 14 million question-solution pairs, including 592,000 synthesized questions, making it about eight times larger than previous open-source datasets. The effectiveness of OpenMathInstruct-2 is demonstrated by the superior performance of fine-tuned models, with OpenMath2-Llama3.1-8B outperforming Llama3.1-8B-Instruct by 15.9% on the MATH benchmark.

OpenMathInstruct-2 demonstrates impressive results across various mathematical reasoning benchmarks. Training details involve using the AdamW optimizer with specific learning rates and weight decay. The 8B model is trained on different subsets of the dataset to understand data scaling effects, while the 70B model is trained on a 5M subset due to computational constraints. Evaluation is conducted on a comprehensive set of benchmarks, including GSM8K, MATH, AMC 2023, AIME 2024, and OmniMATH, covering a wide range of difficulty levels.
The impact of data scaling shows consistent performance gains, with even the 1M subset outperforming Llama3.1-8B-Instruct and NuminaMath-7B-CoT. The OpenMath2-Llama3.1-8B model, trained on the full dataset, outperforms or matches Llama3.1-8B-Instruct across all benchmarks. Among open-source models, it surpasses the recently released NuminaMath-7B-CoT. The 70B model shows improvements on a subset of benchmarks, suggesting that the data blend or solution format might be more suitable for smaller models. Overall, the results demonstrate the effectiveness of the OpenMathInstruct-2 method in enhancing the mathematical reasoning capabilities of language models.


The OpenMathInstruct-2 project makes significant contributions to open-source progress in mathematical reasoning for language models. By releasing a comprehensive dataset, high-performing models, and reproducible code, it advances the field’s understanding of effective dataset construction. The research reveals crucial insights: the importance of optimized chain-of-thought formats, the limitations of on-policy data for supervised fine-tuning, the robustness of models to incorrect solutions during training, and the critical role of question diversity. These findings, coupled with rigorous decontamination processes, ensure accurate benchmark evaluations. This work not only provides valuable resources but also establishes best practices for developing future mathematical reasoning datasets and models.
Check out the Paper and Dataset on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit
Interested in promoting your company, product, service, or event to over 1 Million AI developers and researchers? Let’s collaborate!
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.



