How-To’s
Jupyter notebooks allow you to tell stories by creating and sharing data, equations, and visualizations sequentially, with a supporting narrative as you go through the notebook.
Jupyter notebooks in PyCharm Professional provide functionality above and beyond that of browser-based Jupyter notebooks, such as code completion, dynamic plots, and quick statistics, to help you explore and work with your data quickly and effectively.
Let’s take a look at 7 ways you can use Jupyter notebooks in PyCharm to achieve your goals. They are:
- Creating or connecting to an existing notebook
- Importing your data
- Getting acquainted with your data
- Using JetBrains AI Assistant
- Exploring your code with PyCharm
- Getting insights from your code
- Sharing your insights and charts
The Jupyter notebook that we used in this demo is available on GitHub.
1. Creating or connecting to an existing notebook
You can create and work on your Jupyter notebooks locally or connect to one remotely with PyCharm. Let’s take a look at both options so you can decide for yourself.
Creating a new Jupyter notebook
To work with a Jupyter notebook locally, you need to go to the Project tool window inside PyCharm, navigate to the location where you want to add the notebook, and invoke a new file. You can do this by using either your keyboard shortcuts ⌘N (macOS) / Alt+Ins (Windows/Linux) or by right-clicking and selecting New | Jupyter Notebook.
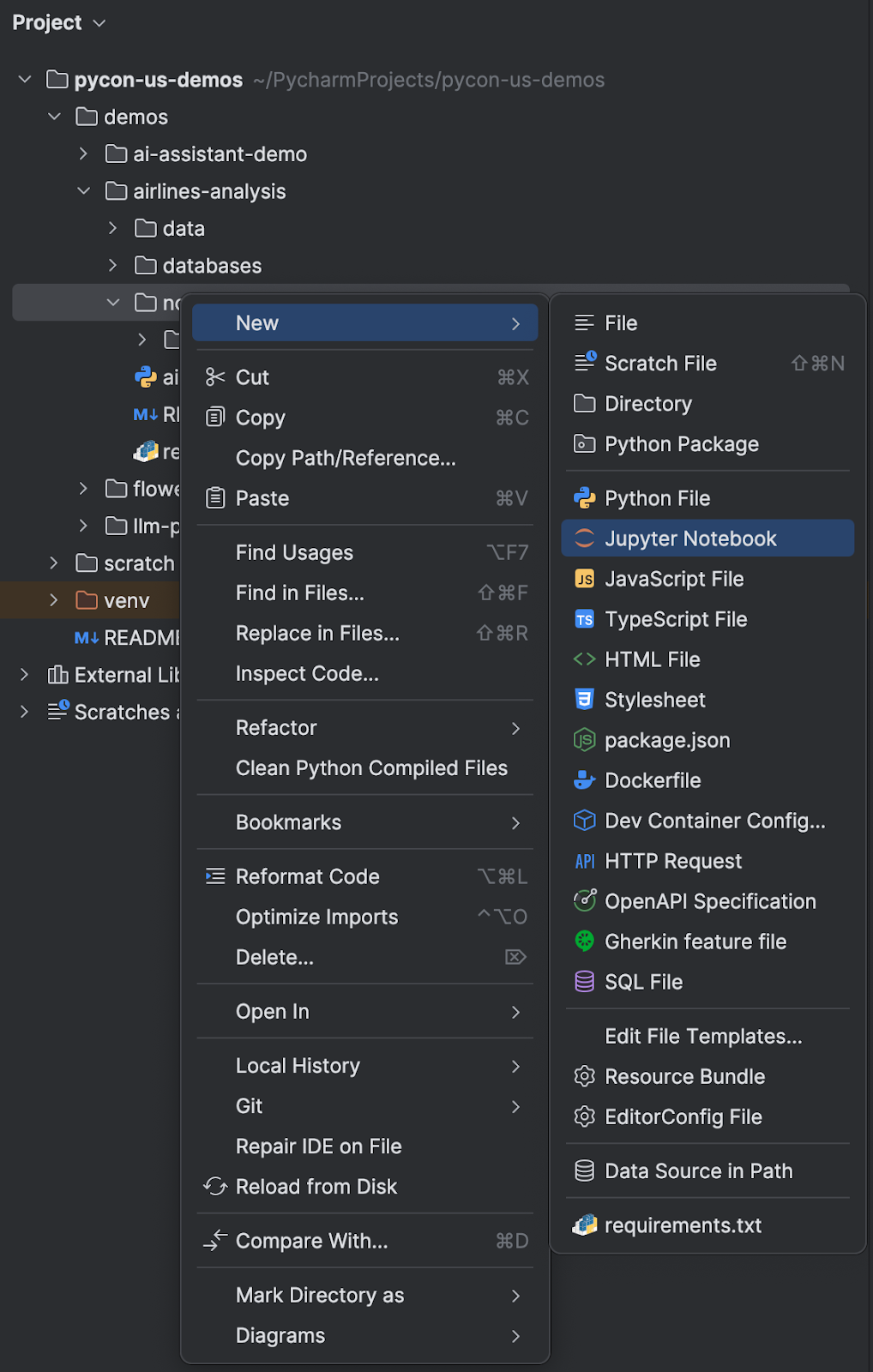
Give your new notebook a name, and PyCharm will open it ready for you to start work. You can also drag local Jupyter notebooks into PyCharm, and the IDE will automatically recognise them for you.
Connecting to a remote Jupyter notebook
Alternatively, you can connect to a remote Jupyter notebook by selecting Tools | Add Jupyter Connection. You can then choose to start a local Jupyter server, connect to an existing running local Jupyter server, or connect to a Jupyter server using a URL – all of these options are supported.
Now you have your Jupyter notebook, you need some data!
2. Importing your data
Data generally comes in two formats, CSV or database. Let’s look at importing data from a CSV file first.
Importing from a CSV file
Polars and pandas are the two most commonly used libraries for importing data into Jupyter notebooks. I’ll give you code for both in this section, and you can check out the documentation for both Polars and pandas and learn how Polars is different to pandas.
You need to ensure your CSV is somewhere in your PyCharm project, perhaps in a folder called `data`. Then, you can invoke import pandas and subsequently use it to read the code in:
import pandas as pd
df = pd.read_csv("../data/airlines.csv")
In this example, airlines.csv is the file containing the data we want to manipulate. To run this and any code cell in PyCharm, use ⇧⏎ (macOS) / Shift+Enter (Windows/Linux). You can also use the green run arrows on the toolbar at the top.
If you prefer to use Polars, you can use this code:
import polars as pl
df = pl.read_csv("../data/airlines.csv")
Importing from a database
If your data is in a database, as is often the case for internal projects, importing it into a Jupyter notebook will require just a few more lines of code. First, you need to set up your database connection. In this example, we’re using postgreSQL.
For pandas, you need to use this code to read the data in:
import pandas as pd
engine = create_engine("postgresql://jetbrains:jetbrains@localhost/demo")
df = pd.read_sql(sql=text("SELECT * FROM airlines"),
con=engine.connect())
And for Polars, it’s this code:
import polars as pl
engine = create_engine("postgresql://jetbrains:jetbrains@localhost/demo")
connection = engine.connect()
query = "SELECT * FROM airlines"
df = pl.read_database(query, connection)
3. Getting acquainted with your data
Now we’ve read our data in, we can take a look at the DataFrame or `df` as we will refer to it in our code. To print out the DataFrame, you only need a single line of code, regardless of which method you used to read the data in:
df
DataFrames
PyCharm displays your DataFrame as a table firstly so you can explore it. You can scroll horizontally through the DataFrame and click on any column header to order the data by that column. You can click on the Show Column Statistics icon on the right-hand side and select Compact or Detailed to get some helpful statistics on each column of data.

Dynamic charts
You can use PyCharm to get a dynamic chart of your DataFrame by clicking on the Chart View icon on the left-hand side. We’re using pandas in this example, but Polars DataFrames also have the same option.
Click on the Show Series Settings icon (a cog) on the right-hand side to configure your plot to meet your needs:

In this view, you can hover your mouse over your data to learn more about it and easily spot outliers:

You can do all of this with Polars, too.
4. Using JetBrains AI Assistant
JetBrains AI Assistant has several offerings that can make you more productive when you’re working with Jupyter notebooks inside PyCharm. Let’s take a closer look at how you can use JetBrains AI Assistant to explain a DataFrame, write code, and even explain errors.
Explaining DataFrames
If you’ve got a DataFrame but are unsure where to start, you can click the purple AI icon on the right-hand side of the DataFrame and select Explain DataFrame. JetBrains AI Assistant will use its context to give you an overview of the DataFrame:

You can use the generated explanation to aid your understanding.
Writing Code
You can also get JetBrains AI Assistant to help you write code. Perhaps you know what kind of plot you want, but you’re not 100% sure what the code should look like. Well, now you can use JetBrains AI Assistant to help you. Let’s say you want to use ‘matplotlib’ to create a chart that finds the relationship between ‘TimeMonthName’ and ‘MinutesDelayedWeather’. By specifying the column names, we’re giving more context to the request which improves the reliability of the generated code. Try it with the following prompt:
Give me code using matplotlib to create a chart which finds the relationship between ‘TimeMonthName’ and ‘MinutesDelayedWeather’ for my dataframe df
If you like the resulting code, you can use the Insert Snippet at Caret button to insert the code and then run it:
import matplotlib.pyplot as plt
# Assuming your data is in a DataFrame named 'df'
# Replace 'df' with the actual name of your DataFrame if different
# Plotting
plt.figure(figsize=(10, 6))
plt.bar(df['TimeMonthName'], df['MinutesDelayedWeather'], color="skyblue")
plt.xlabel('Month')
plt.ylabel('Minutes Delayed due to Weather')
plt.title('Relationship between TimeMonthName and MinutesDelayedWeather')
plt.xticks(rotation=45)
plt.grid(axis="y", linestyle="--", alpha=0.7)
plt.tight_layout()
plt.show()
If you don’t want to open the AI Assistant tool window, you can use the AI cell prompt to ask your questions. For example, we can ask the same question here and get the code we need:
Explaining errors
You can also get JetBrains AI Assistant to explain errors for you. When you get an error, click Explain with AI:

You can use the resulting output to further your understanding of the problem and perhaps even get some code to fix it!
5. Exploring your code
PyCharm can help you get an overview of your Jupyter notebook, complete parts of your code to save your fingers, refactor it as required, debug it, and even add integrations to help you take it to the next level.
Tips for navigating and optimizing your code
Our Jupyter notebooks can grow large quite quickly, but thankfully you can use PyCharm’s Structure view to see all your notebook’s headings by clicking ⌘7 (macOS) / Alt+7 (Windows/Linux).

Code completion
Another helpful feature that you can take advantage of when using Jupyter notebooks inside PyCharm is code completion. You get both basic and type-based code completion out of the box with PyCharm, but you can also enable Full Line Code Completion in PyCharm Professional, which uses a local AI model to provide suggestions. Lastly, JetBrains AI Assistant can also help you write code and discover new libraries and frameworks.

Refactoring
Sometimes you need to refactor your code, and in that case, you only need to know one keyboard shortcut ⌃T (macOS) / Shift+Ctrl+Alt+T (Windows/Linux) then you can choose the refactoring you want to invoke. Pick from popular options such as Rename, Change Signature, and Introduce Variable, or lesser-known options such as Extract Method, to change your code without changing the semantics:

As your Jupyter notebook grows, it’s likely that your import statements will also grow. Sometimes you might import a package such as polars and numpy, but forget that numpy is a transitive dependency of the Polars library and as such, we don’t need to import it separately.
To catch these cases and keep your code tidy, you can invoke Optimize Imports ⌃⌥O (macOS) / Ctrl+Alt+O (Windows/Linux) and PyCharm will remove the ones you don’t need.
Debugging your code
You might not have used the debugger in PyCharm yet, and that’s okay. Just know that it’s there and ready to support you when you need to better understand some behavior in your Jupyter notebook.
Place a breakpoint on the line you’re interested in by clicking in the gutter or by using ⌘F8 (macOS) / Ctrl+F8 (Windows/Linux), and then run your code with the debugger attached with the debug icon on the top toolbar:

You can also invoke PyCharm’s debugger in your Jupyter notebook with ⌥⇧⏎ (macOS) / Shift+Alt+Enter (Windows/Linux). There are some restrictions when it comes to debugging your code in a Jupyter notebook, but please try this out for yourself and share your feedback with us.
Adding integrations into PyCharm
IDEs wouldn’t be complete without the integrations you need. PyCharm Professional 2024.2 brings two new integrations to your workflow: DataBricks and HuggingFace.
You can enable the integrations with both Databricks and HuggingFace by going to your Settings <kbd>⌘</kbd> (macOS) / <kbd>Ctrl+Alt+S</kbd> (Windows/Linux), selecting Plugins and searching for the plugin with the corresponding name on the Marketplace tab.
6. Getting insights from your code
When analyzing your data, there’s a difference between categorical and continuous variables. Categorical data has a finite number of discrete groups or categories, whereas continuous data is one continuous measurement. Let’s look at how we can extract different insights from both the categorical and continuous variables in our airlines dataset.
Continuous variables
We can get a sense of how continuous data is distributed by looking at measures of the average value in that data and the spread of the data around the average. In normally distributed data, we can use the mean to measure the average and the standard deviation to measure the spread. However, when data is not distributed normally, we can get more accurate information using the median and the interquartile range (this is the difference between the seventy-fifth and twenty-fifth percentiles). Let’s look at one of our continuous variables to understand the difference between these measurements.
In our dataset, we have lots of continuous variables, but we’ll work with `NumDelaysLateAircraft` to see what we can learn. Let’s use the following code to get some summary statistics for just that column:
df['NumDelaysLateAircraft'].describe()
Looking at this data, we can see that there is a big difference between the `mean` of ~789 and the ‘median’ (our fiftieth percentile, indicated by “50%” in the table below) of ~618.

This indicates a skew in our variable’s distribution, so let’s use PyCharm to explore it further. Click on the Chart View icon at the top left. Once the chart has been rendered, we’ll change the series settings represented by the cog on the right-hand side of the screen. Change your x-axis to `NumDelaysLateAircraft` and your y-axis to `NumDelaysLateAircraft`.
Now drop down the y-axis using the little arrow and select `count`. The final step is to change the chart type to Histogram using the icons in the top-right corner:

Now that we can see the skew laid out visually, we can see that most of the time, the delays are not too excessive. However, we have a number of more extreme delays – one aircraft is an outlier on the right and it was delayed by 4,509 minutes, which is just over three days!
In statistics, the mean is very sensitive to outliers because it’s a geometric average, unlike the median, which, if you ordered all observations in your variable, would sit exactly in the middle of these values. When the mean is higher than the median, it’s because you have outliers on the right-hand side of the data, the higher side, as we had here. In such cases, the median is a better indicator of the true average delay, as you can see if you look at the histogram.
Categorical variables
Let’s take a look at how we can use code to get some insights from our categorical variables. In order to get something that’s a little more interesting than just `AirportCode`, we’ll analyze how many aircraft were delayed by weather, `NumDelaysWeather`, in the different months of the year, `TimeMonthName`.
Use this code to group `NumDelaysWeather` with `TimeMonthName`:
result = df[['TimeMonthName', 'NumDelaysWeather']].groupby('TimeMonthName').sum()
result
This gives us the DataFrame again in table format, but click the Chart View icon on the left-hand side of the PyCharm UI to see what we can learn:

This is okay, but it would be helpful to have the months ordered according to the Gregorian calendar. Let’s first create a variable for the months that we expect:
month_order = [ "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December" ]
Now we can ask PyCharm to use the order that we’ve just defined in `month_order`:
# Convert the 'TimeMonthName' column to a categorical type with the specified order
df["TimeMonthName"] = pd.Categorical(df["TimeMonthName"], categories=month_order, ordered=True)
# Now you can group by 'TimeMonthName' and perform sum operation, specifying observed=False
result = df[['TimeMonthName', 'NumDelaysWeather']].groupby('TimeMonthName', observed=False).sum()
result
We then click on the Chart View icon once more, but something’s wrong!

Are we really saying that there were no flights delayed in February? That can’t be right. Let’s check our assumption with some more code:
df['TimeMonthName'].value_counts()
Aha! Now we can see that `Febuary` has been misspelt in our data set, so the correct spelling in our variable name does not match. Let’s update the spelling in our dataset with this code:
df["TimeMonthName"] = df["TimeMonthName"].replace("Febuary", "February")
df['TimeMonthName'].value_counts()
Great, that looks right. Now we should be able to re-run our earlier code and get a chart view that we can interpret:

From this view, we can see that there is a higher number of delays during the months of December, January, and February, and then again in June, July, and August. However, we have not standardized this data against the total number of flights, so there may just be more flights in those months, which would cause these results along with an increased number of delays in those summer and winter months.
7. Sharing your insights and charts
When your masterpiece is complete, you’ll probably want to export data, and you can do that in various ways with Jupyter notebooks in PyCharm.
Exporting a DataFrame
You can export a DataFrame by clicking on the down arrow on the right-hand side:

You have lots of helpful formats to choose from, including SQL, CSV, and JSON:

Exporting charts
If you prefer to export the interactive plot, you can do that too by clicking on the Export to PNG icon on the right-hand side:

Viewing your notebook as a browser
You can view your whole Jupyter notebook at any time in a browser by clicking the icon in the top-right corner of your notebook:

Finally, if you want to export your Jupyter notebook to a Python file, 2024.2 lets you do that too! Right-click on your Jupyter notebook in the Project tool window and select Convert to Python File. Follow the instructions, and you’re done!
Summary
Using Jupyter notebooks inside PyCharm Professional provides extensive functionality, enabling you to create code faster, explore data easily, and export your projects in the formats that matter to you.
Download PyCharm Professional to try it out for yourself! Get an extended trial today and experience the difference PyCharm Professional can make in your data science endeavors.
Use the promo code “PyCharmNotebooks” at checkout to activate your free 60-day subscription to PyCharm Professional. The free subscription is available for individual users only.

Subscribe to PyCharm Blog updates